
HBase基本操作整理
HBase数据模型
HBase逻辑架构
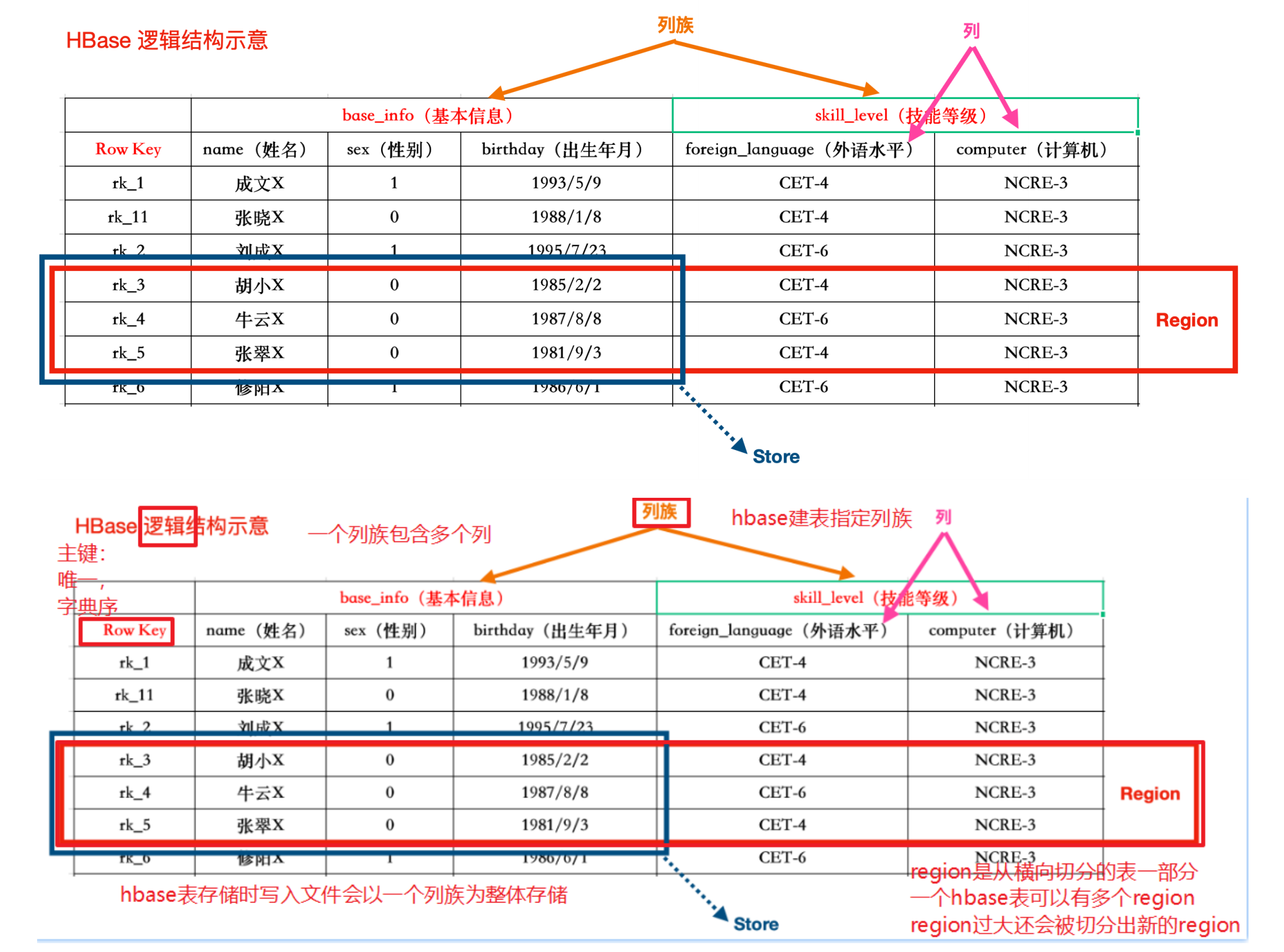
HBase物理存储

概念描述

HBase整体架构
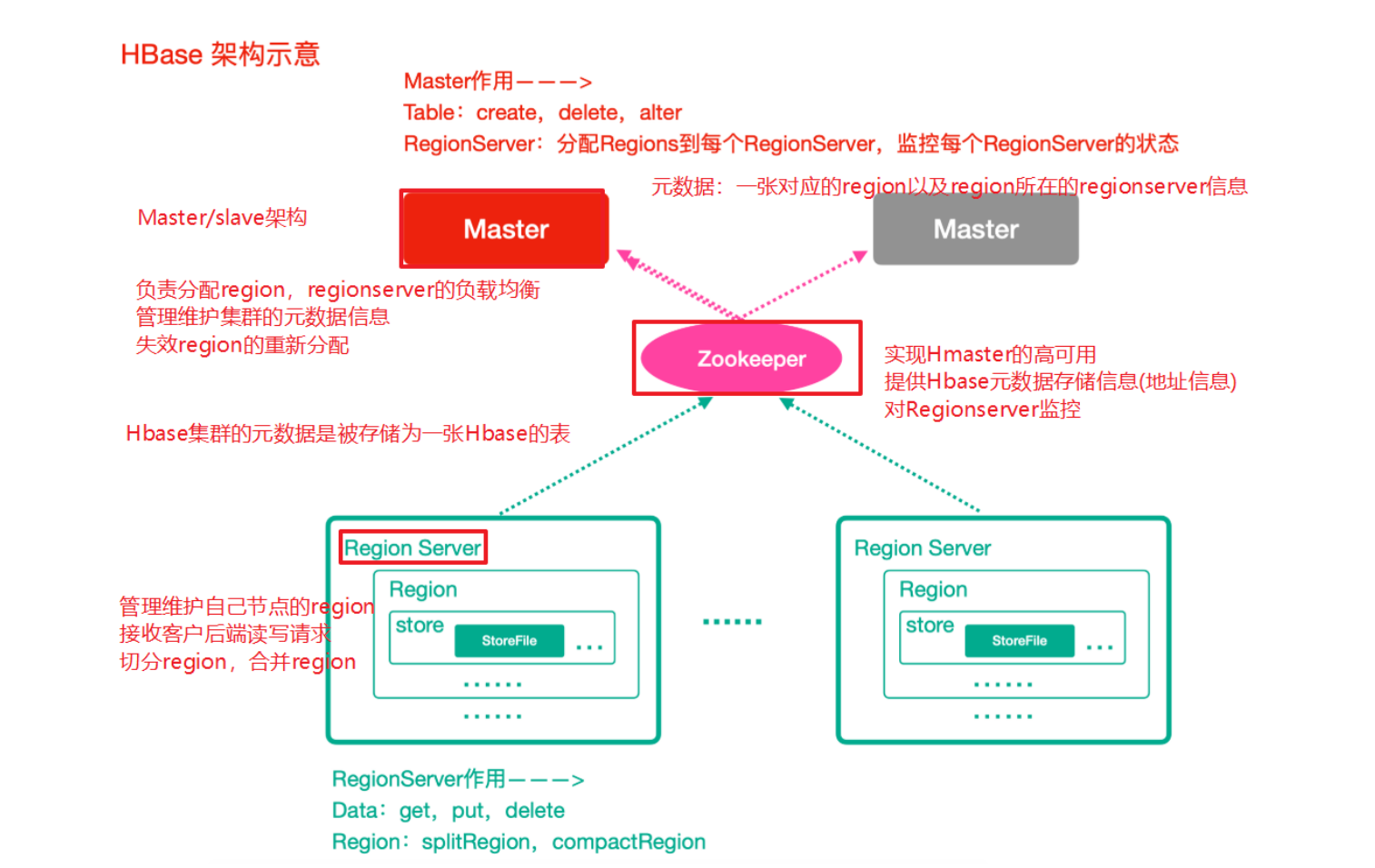
Zookeeper
- 实现了HMaster的⾼可⽤
- 保存了HBase的元数据信息,是所有HBase表的寻址⼊⼝
- 对HMaster和HRegionServer实现了监控
HMaster(Master)
- 为HRegionServer分配Region
- 维护整个集群的负载均衡
- 维护集群的元数据信息
- 发现失效的Region,并将失效的Region分配到正常的HRegionServer上
HRegionServer(RegionServer)
- 负责管理Region
- 接受客户端的读写数据请求
- 切分在运⾏过程中变⼤的Region
Region
- 每个HRegion由多个Store构成,
- 每个Store保存⼀个列族(Columns Family),表有⼏个列族,则有⼏个Store,
- 每个Store由⼀个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到⽂件后就是StoreFile。StoreFile底层是以HFile的格式保存。
HBase启动
1 | 前提条件:先启动hadoop和zk集群 |
HBase shell
基本操作
1 | 1、进⼊Hbase客户端命令操作界⾯ |
创建table
创建了一个student table,有两个列族info和score,分别用来存放学生的个人信息和成绩
1 | hbase(main):005:0> create 'student','info','score' |
put数据
对table student插入一行数据,rowKey为r1,列族属于info,列属于name,值为’xiaoyuyu’
1 | hbase(main):008:0> put 'student','r1','info:name','xiaoyuyu' |
get数据
查询table student中rowKey为人r1的数据
1 | hbase(main):014:0> get 'student','r1' |
查询某一rowKey某一个列族的信息
1 | hbase(main):015:0> get 'student','r1','info' |
查询某一rowKey某一列的数据
1 | hbase(main):017:0> get 'student','r1','info:age' |
特定列值查询
1 | hbase(main):020:0> get 'student','r1',{FILTER=>"ValueFilter(=,'binary:80')"} |
列值模糊查询
1 | 这个模糊查询的是列名,不是值 |
scan数据
查询所有数据
1 | hbase(main):031:0> scan 'student' |
查询表中列族为 info 的信息
1 | 直接scan 'student','info'是不行的,这点不是很统一 |
指定多个列族与按照数据值模糊查询
1 | hbase(main):034:0> scan 'student',{COLUMNS => ['info'],FILTER=>"QualifierFilter(=,'substring:ag')"} |
rowkey的范围值查询(⾮常重要)
1 | rowkey底层存储是字典序 |
指定rowkey模糊查询
1 | hbase(main):035:0> scan 'student',{FILTER=>"PrefixFilter('r')"} |
put更新数据
更新操作同插⼊操作⼀模⼀样,只不过有数据就更新,没数据就添加
1 | hbase(main):038:0> put 'student','r2','score:english',100 |
delete删除
指定rowkey以及列名进⾏删除
1 | hbase(main):040:0> delete 'student','r1','info:address' |
删除列族
1 | hbase(main):042:0> alter 'student','delete'=>'score' |
清空table的数据
1 | hbase(main):044:0> truncate 'student' |
删除表
1 | 先disable 再drop |
HBase原理深⼊
HBase读数据流程
总体和bigtable论文中的三层逻辑比较相似,读论文还是有好处的,这里的zookeeper就实现了Chubby的功能。可以看到读写数据和master没有产生交互。
1)⾸先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了⽤户表的region信息
2)根据要查询的namespace、表名和rowkey信息。找到写⼊数据对应的region信息
3)找到这个region对应的regionServer,然后发送请求
4)查找对应的region
5)先从memstore查找数据,如果没有,再从BlockCache上读取
HBase上Regionserver的内存分为两个部分
⼀部分作为Memstore,主要⽤来写;
另外⼀部分作为BlockCache,主要⽤于读数据;
6)如果BlockCache中也没有找到,再到StoreFile上进⾏读取
从storeFile中读取到数据之后,不是直接把结果数据返回给客户端, ⽽是把数据先写⼊到BlockCache中,⽬的是为了加快后续的查询;然后在返回结果给客户
端。

HBase写数据流程
1)⾸先从zk找到meta表的region位置,然后读取meta表中的数据,meta表中存储了⽤户表的region信息
2)根据namespace、表名和rowkey信息。找到写⼊数据对应的region信息
3)找到这个region对应的regionServer,然后发送请求
4)把数据分别写到HLog(write ahead log)和memstore各⼀份
5)memstore达到阈值后把数据刷到磁盘,⽣成storeFile⽂件
6)删除HLog中的历史数据

总体还是比较清晰的,同样不需要master的干预。
HBase的flush(刷写)及compact(合并)机制
我们之前可以看到memstore有一个flush的操作,同时storefile还会有合并的动作,这里主要关心一下如何配置
Flush机制
(1)当memstore的⼤⼩超过这个值的时候,会flflush到磁盘,默认为128M
1 | <property> |
(2)当memstore中的数据时间超过1⼩时,会flflush到磁盘
1 | <property> |
(3)HregionServer的全局memstore的⼤⼩,超过该⼤⼩会触发flflush到磁盘的操作,默认是堆⼤⼩的40%
1 | <property> |
(4)⼿动flflush
flush tableName
阻塞机制
如果一直往memstore写入显然是不合理的,源源不断的数据写入,早晚会爆掉,Hbase中是周期性的检查是否满⾜以上标准满⾜则进⾏刷写,但是如果在下次检查到来之前,数据疯狂写⼊Memstore中需要一定的控制,阻塞机制就针对这点进行处理。
memstore中数据达到512MB
计算公式:hbase.hregion.memstore.flflush.size*hbase.hregion.memstore..block.multiplier
hbase.hregion.memstore.flflush.size刷写的阀值,默认是 134217728,即128MB。
hbase.hregion.memstore.block.multiplier是⼀个倍数,默认 是4。
RegionServer全部memstore达到规定值
hbase.regionserver.global.memstore.size.lower.limit是0.95,
hbase.regionserver.global.memstore.size是0.4,
堆内存总共是 16G,
触发刷写的阈值是:6.08GB 触发阻塞的阈值是:6.4GB
Compact合并机制
合并文件这里主要考虑storefile的合并,主要分为两种,小文件合并和大文件合并
minor compact ⼩合并
在将Store中多个HFile(StoreFile)合并为⼀个HFile
这个过程中,删除和更新的数据仅仅只是做了标记,并没有物理移除,这种合并的触发频率很⾼。
minor compact⽂件选择标准由以下⼏个参数共同决定:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43<!--待合并⽂件数据必须⼤于等于下⾯这个值-->
<property>
<name>hbase.hstore.compaction.min</name>
<value>3</value>
</property>
<!--待合并⽂件数据必须⼩于等于下⾯这个值-->
<property>
<name>hbase.hstore.compaction.max</name>
<value>10</value></property>
<!--默认值为128m,
表示⽂件⼤⼩⼩于该值的store file ⼀定会加⼊到minor compaction的store file中
-->
<property>
<name>hbase.hstore.compaction.min.size</name>
<value>134217728</value>
</property>
<!--默认值为LONG.MAX_VALUE,
表示⽂件⼤⼩⼤于该值的store file ⼀定会被minor compaction排除-->
<property>
<name>hbase.hstore.compaction.max.size</name>
<value>9223372036854775807</value>
</property>
major compact ⼤合并
合并Store中所有的HFile为⼀个HFile
这个过程有删除标记的数据会被真正移除,同时超过单元格maxVersion的版本记录也会被删除。合并频率⽐较低,默认7天执⾏⼀次,并且性能消耗⾮常⼤,建议⽣产关闭(设置为0),在应⽤空闲时间⼿动触发。⼀般可以是⼿动控制进⾏合并,防⽌出现在业务⾼峰期。
major compaction触发时间条件
1
2
3
4
5
6
7
8
9<!--默认值为7天进⾏⼀次⼤合并,-->
<property>
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
</property>⼿动触发
1
2#使⽤major_compact命令
major_compact tableName
Region 拆分机制
Region中存储的是⼤量的rowkey数据 ,当Region中的数据条数过多的时候,直接影响查询效率.当Region过⼤的时候.HBase会拆分Region , 这也是Hbase的⼀个优点 。
首先同一个列族才会存放在同一个region,这点需要注意。
具体分区策略可以在官方文档查看,种类比较多,也可以自定义拆分策略。
HBase表的预分区(region)
当⼀个table刚被创建的时候,Hbase默认的分配⼀个region给table。也就是说这个时候,所有的读写请求都会访问到同⼀个regionServer的同⼀个region中,这个时候就达不到负载均衡的效果了,集群中的其他regionServer就可能会处于⽐较空闲的状态。解决这个问题可以⽤pre-splitting,在创建table的时候就配置好,⽣成多个region。
- 增加数据读写效率
- 负载均衡,防⽌数据倾斜
- ⽅便集群容灾调度region
每⼀个region维护着startRow与endRowKey,如果加⼊的数据符合某个region维护的rowKey范围,则该数据交给这个region维。
⼿动指定预分区
1 | create 'person','info1','info2',SPLITS => ['1000','2000','3000'] |
也可以把分区规则创建于⽂件中
1 | vim split.txt |
⽂件内容
1 | aaa |
执⾏
1 | create 'student','info',SPLITS_FILE => '/root/hbase/split.txt' |
Region 合并
Region的合并不是为了性能,⽽是出于维护的⽬的。
有冷合并和热合并两种,冷合并需要关闭hbase集群,热合并直接在hbase shell进行即可。
本文链接: http://woaixiaoyuyu.github.io/2021/10/08/HBase%E6%93%8D%E4%BD%9C%E7%AC%94%E8%AE%B0/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!