
平时学习的一些调优技巧和调优思路整理,会不断更新。
Hadoop
MapReduce中的map个数
在map阶段读取数据前,FileInputFormat会将输入文件分割成split。split的个数决定了map的个数。影响map个数(split个数)的主要因素有:
文件的大小。当块(dfs.block.size)为128m时,如果输入文件为128m,会被划分为1个split;当块为256m,会被划分为2个split。
文件的个数。FileInputFormat按照文件分割split,并且只会分割大文件,即那些大小超过HDFS块的大小的文件。如果HDFS中dfs.block.size设置为128m,而输入的目录中文件有100个,则划分后的split个数至少为100个。
splitsize的大小。分片是按照splitszie的大小进行分割的,一个split的大小在没有设置的情况下,默认等于hdfs block的大小。但应用程序可以通过两个参数来对splitsize进行调节
$InputSplit=Math.max(minSize, Math.min(maxSize, blockSize)$
总结如下:
- 当mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize > dfs.blockSize的情况下,此时的splitSize 将由mapreduce.input.fileinputformat.split.minsize参数决定
- 当mapreduce.input.fileinputformat.split.maxsize > dfs.blockSize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize 将由dfs.blockSize配置决定
- 当dfs.blockSize > mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize将由mapreduce.input.fileinputformat.split.maxsize参数决定。
spark
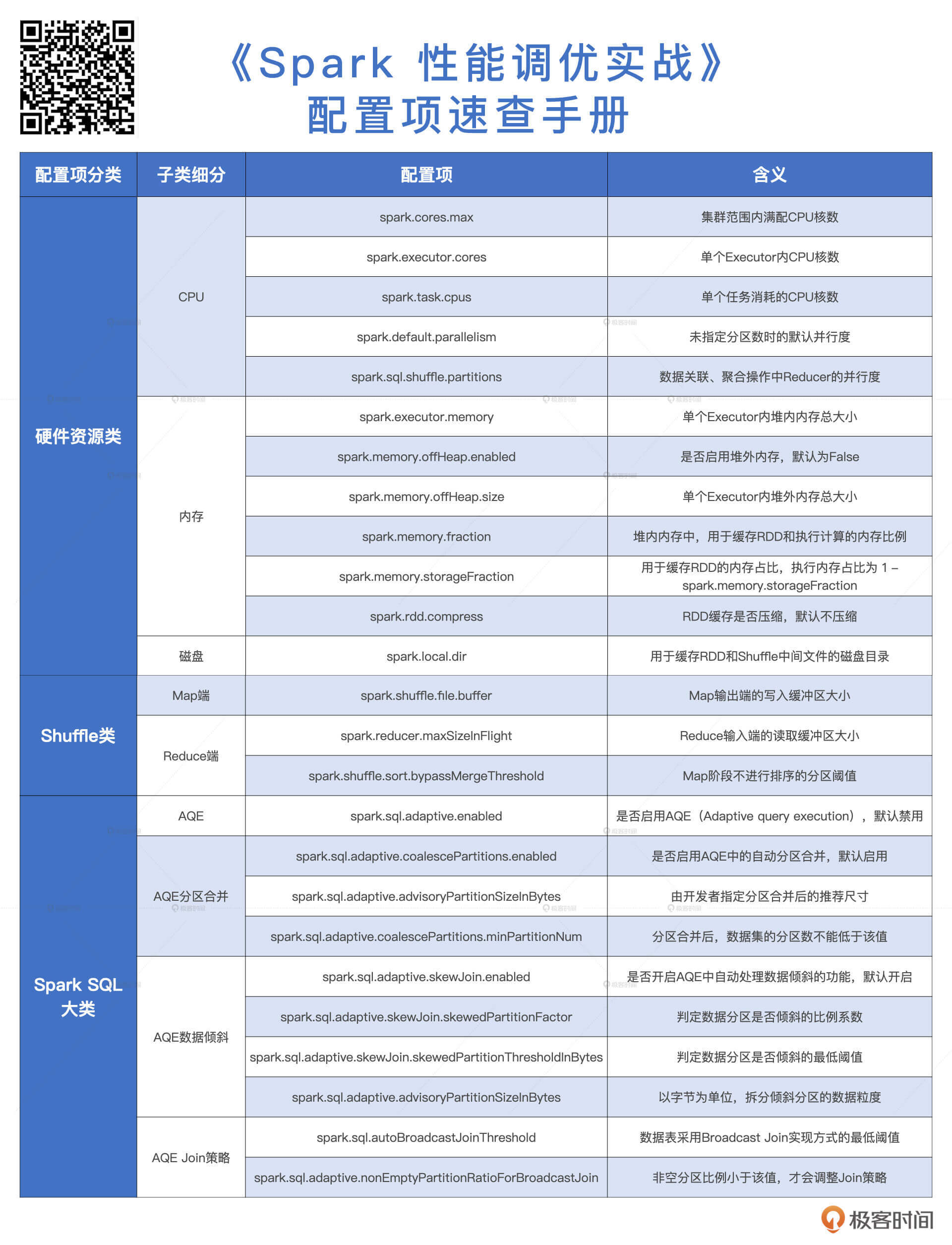
配置项的分类
在 Spark 分布式计算环境中,计算负载主要由 Executors 承担,Driver 主要负责分布式调度,调优空间有限,因此对 Driver 端的配置项我们不作考虑,我们要汇总的配置项都围绕 Executors 展开。那么,结合过往的实践经验,以及对官网全量配置项的梳理,我把它们划分为 3 类,分别是硬件资源类、Shuffle 类和 Spark SQL 大类。
- 首先,硬件资源类包含的是与 CPU、内存、磁盘有关的配置项
- 其次,Shuffle 类是专门针对 Shuffle 操作的
- 最后,Spark SQL 早已演化为新一代的底层优化引擎
spark.sql.shuffle.partitions
spark.sql.shuffle.partitions: 设置的是 RDD1做shuffle处理后生成的结果RDD2的分区数.默认值: 200
spark.default.parallelism: 设置的是 RDD1做shuffle处理/并行处理(窄依赖算子)后生成的结果RDD2的分区数默认值:
为了充分利用划拨给 Spark 集群的每一颗 CPU,准确地说是每一个 CPU 核(CPU Core),你需要设置与之匹配的并行度,并行度用 spark.default.parallelism 和 spark.sql.shuffle.partitions 这两个参数设置。对于没有明确分区规则的 RDD 来说,我们用 spark.default.parallelism 定义其并行度,spark.sql.shuffle.partitions 则用于明确指定数据关联或聚合操作中 Reduce 端的分区数量。
spark并行度
并行度其实就是指的是spark作业中, 各个stage的taskset中的task的数量, 代表了spark作业中各个阶段的并行度, 而taskset中的task数量 = task任务的父RDD中分区数。
官网建议: 设置为当前spark job的总core数量的2~3倍。
spark.sql.files.maxPartitionBytes
The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC.
spark.sql.files.minPartitionNum
The suggested (not guaranteed) minimum number of split file partitions. If not set, the default value is spark.default.parallelism. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC.
AQE
自动分区合
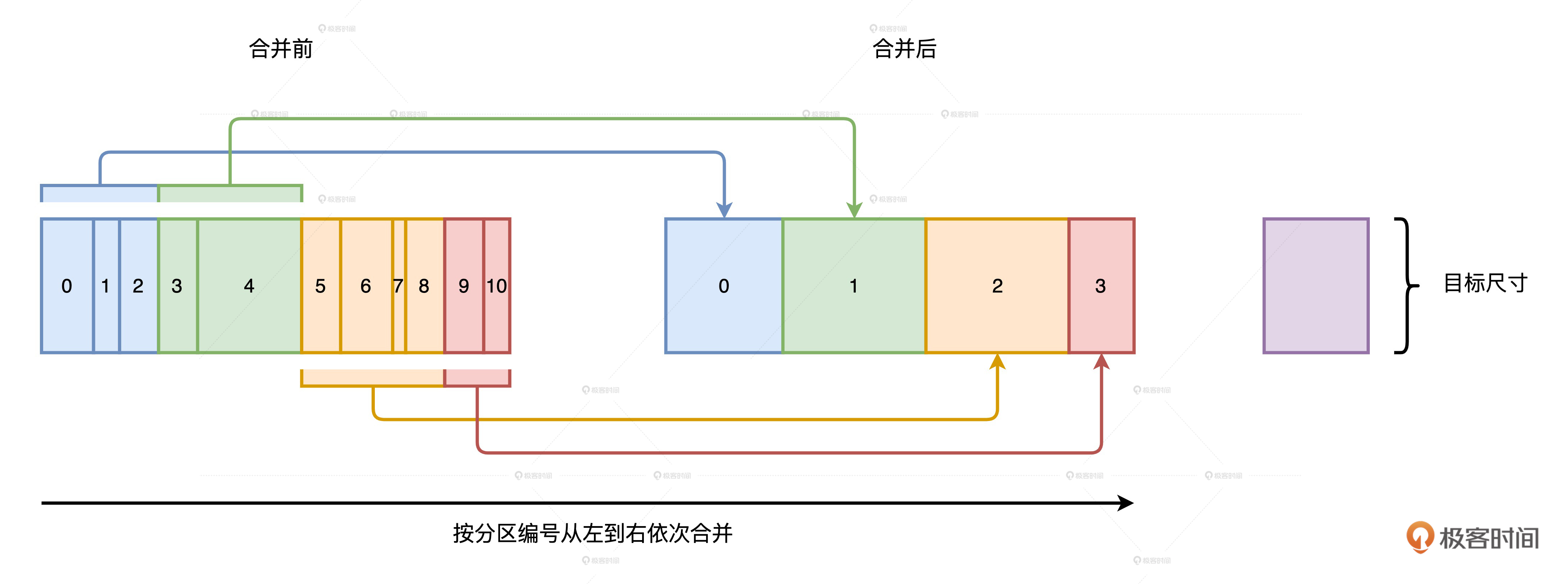
我们一起来看一下 AQE 分区合并的工作原理。如上图所示,对于所有的数据分区,无论大小,AQE 按照分区编号从左到右进行扫描,边扫描边记录分区尺寸,当相邻分区的尺寸之和大于“目标尺寸”时,AQE 就把这些扫描过的分区进行合并。然后,继续向右扫描,并采用同样的算法,按照目标尺寸合并剩余分区,直到所有分区都处理完毕。
总的来说就是,AQE 事先并不判断哪些分区足够小,而是按照分区编号进行扫描,当扫描量超过“目标尺寸”时,就合并一次。我们发现,这个过程中的关键就是“目标尺寸”的确定,它的大小决定了合并之后分布式数据集的分散程度。
自动数据倾斜处理
首先,分区尺寸必须要大于 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 参数的设定值,才有可能被判定为倾斜分区。然后,AQE 统计所有数据分区大小并排序,取中位数作为放大基数,尺寸大于中位数一定倍数的分区会被判定为倾斜分区,中位数的放大倍数也是由参数 spark.sql.adaptive.skewJoin.skewedPartitionFactor 控制。
检测到倾斜分区之后,接下来就是对它拆分,拆分的时候还会用到 advisoryPartitionSizeInBytes 参数。
Join 策略调整
AQE 很好地解决了这两个头疼的问题。首先,AQE 的 Join 策略调整是一种动态优化机制,对于刚才的两张大表,AQE 会在数据表完成过滤操作之后动态计算剩余数据量,当数据量满足广播条件时,AQE 会重新调整逻辑执行计划,在新的逻辑计划中把 Shuffle Joins 降级为 Broadcast Join。再者,运行时的数据量估算要比编译时准确得多,因此 AQE 的动态 Join 策略调整相比静态优化会更可靠、更稳定。
什么是shuffle
Shuffle 的计算过程分为 Map 和 Reduce 这两个阶段。其中,Map 阶段执行映射逻辑,并按照 Reducer 的分区规则,将中间数据写入到本地磁盘;Reduce 阶段从各个节点下载数据分片,并根据需要实现聚合计算。
为什么reduceByKey优于groupByKey
之前我们也说过,Map 阶段最终生产的数据会以中间文件的形式物化到磁盘中,这些中间文件就存储在 spark.local.dir 设置的文件目录里。中间文件包含两种类型:一类是后缀为 data 的数据文件,存储的内容是 Map 阶段生产的待分发数据;另一类是后缀为 index 的索引文件,它记录的是数据文件中不同分区的偏移地址。这里的分区是指 Reduce 阶段的分区,因此,分区数量与 Reduce 阶段的并行度保持一致。
这样一来,我们就可以把问题进一步聚焦在,Spark 在 Map 阶段是如何生产这些中间文件的。不过,我们首先需要明确的是,Map 阶段每一个 Task 的执行流程都是一样的,每个 Task 最终都会生成一个数据文件和一个索引文件。因此,中间文件的数量与 Map 阶段的并行度保持一致。换句话说,有多少个 Task,Map 阶段就会生产相应数量的数据文件和索引文件。
groupByKey
groupByKey 是 pairRDD 算子,需要消费(Key,Value)形式的数据,因此我们需要对原始花朵数据做一次转换。
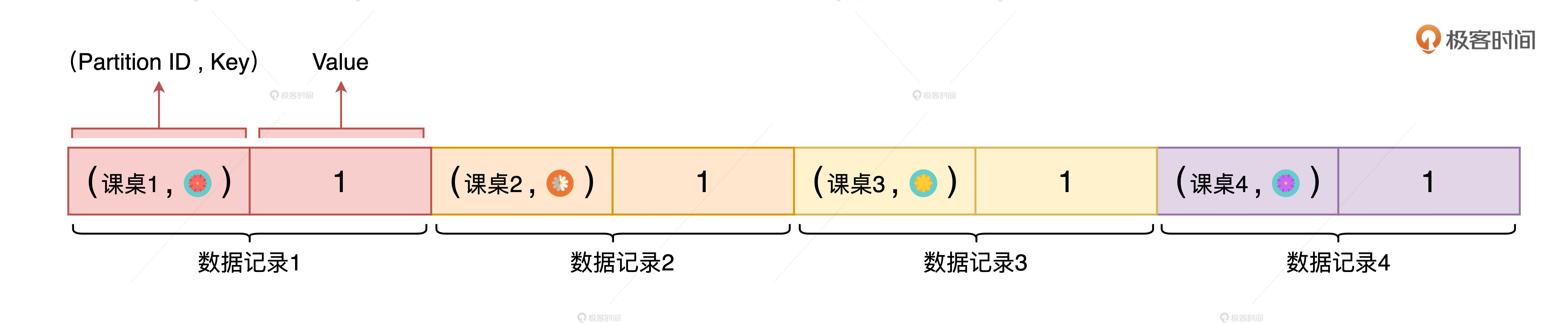
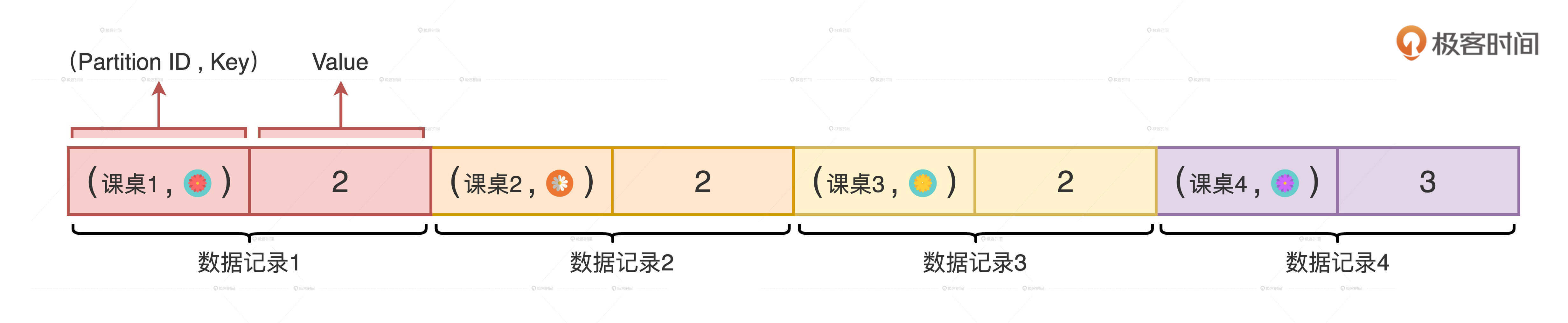
目标分区计算好之后,Map Task 会把每条数据记录和它的目标分区,放到一个特殊的数据结构里,这个数据结构叫做“PartitionedPairBuffer”,它本质上就是一种数组形式的缓存结构。
每条数据记录都会占用数组中相邻的两个元素空间,第一个元素是(目标分区,Key),第二个元素是 Value。假设 PartitionedPairBuffer 的大小是 4,也就是最多只能存储 4 条数据记录。那么,如果我们还以数据分区 0 为例,前 四条数据在 PartitionedPairBuffer 中的存储状态就会如下所示。
对我们来说,最理想的情况当然是 PartitionedPairBuffer 足够大,大到足以容纳 Map Task 所需处理的所有数据。不过,现实总是很骨感,每个 Task 分到的内存空间是有限的,PartitionedPairBuffer 自然也不能保证能容纳分区中的所有数据。因此,Spark 需要一种计算机制,来保障在数据总量超出可用内存的情况下,依然能够完成计算。这种机制就是:排序、溢出、归并。
不过,在溢出之前,对于 PartitionedPairBuffer 中已有的数据,Map Task 会先按照数据记录的第一个元素,也就是目标分区 + Key 进行排序。也就是说,尽管数据暂时溢出到了磁盘,但是临时文件中的数据也是有序的。
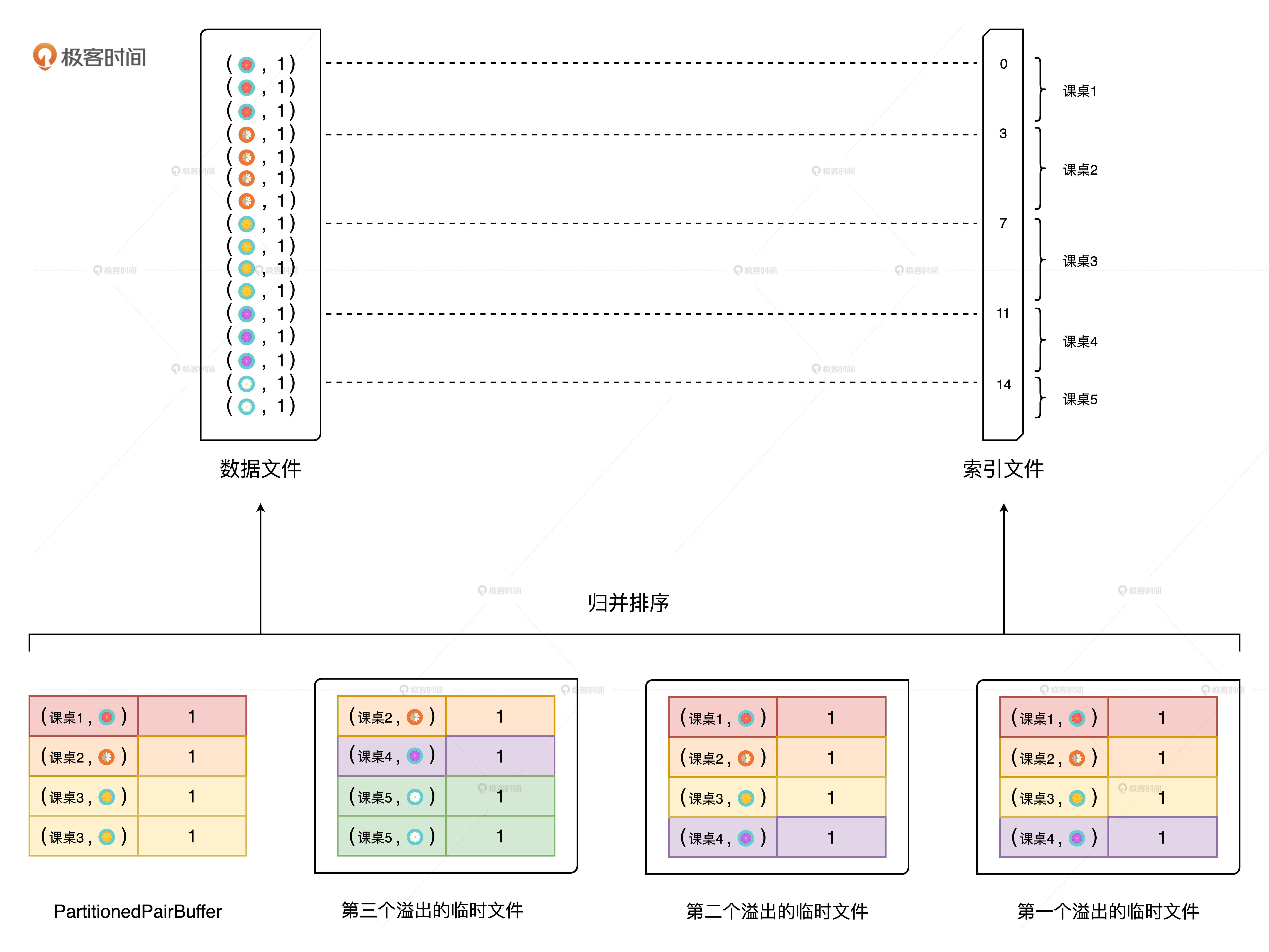
- 对于分片中的数据记录,逐一计算其目标分区,并将其填充到 PartitionedPairBuffer;
- PartitionedPairBuffer 填满后,如果分片中还有未处理的数据记录,就对 Buffer 中的数据记录按(目标分区 ID,Key)进行排序,将所有数据溢出到临时文件,同时清空缓存;
- 重复步骤 1、2,直到分片中所有的数据记录都被处理;
- 对所有临时文件和 PartitionedPairBuffer 归并排序,最终生成数据文件和索引文件。
reduceByKey
区别在于,在计算的过程中,reduceByKey 采用一种叫做 PartitionedAppendOnlyMap 的数据结构来填充数据记录。这个数据结构是一种 Map,而 Map 的 Value 值是可累加、可更新的。因此,PartitionedAppendOnlyMap 非常适合聚合类的计算场景,如计数、求和、均值计算、极值计算等等。
在 PartitionedAppendOnlyMap 中,由于 Value 是可累加、可更新的,因此这种数据结构可以容纳的花朵数量一定比 4 大。因此,相比 PartitionedPairBuffer,PartitionedAppendOnlyMap 的存储效率要高得多,溢出数据到磁盘文件的频率也要低得多。
以此类推,最终合并的数据文件也会小很多。依靠高效的内存数据结构、更少的磁盘文件、更小的文件尺寸,我们就能大幅降低了 Shuffle 过程中的磁盘和网络开销。
事实上,相比 groupByKey、collect_list 这些收集类算子,聚合类算子(reduceByKey、aggregateByKey 等)在执行性能上更占优势。因此,我们要避免在聚合类的计算需求中,引入收集类的算子。虽然这种做法不妨碍业务逻辑实现,但在性能调优上可以说是大忌。
比groupByKey生产的中间文件size小,因为做过map端的预聚合,所以节省了空间,也节省了时间开销。
广播变量如何克制shuffle
概念
不实用广播变量
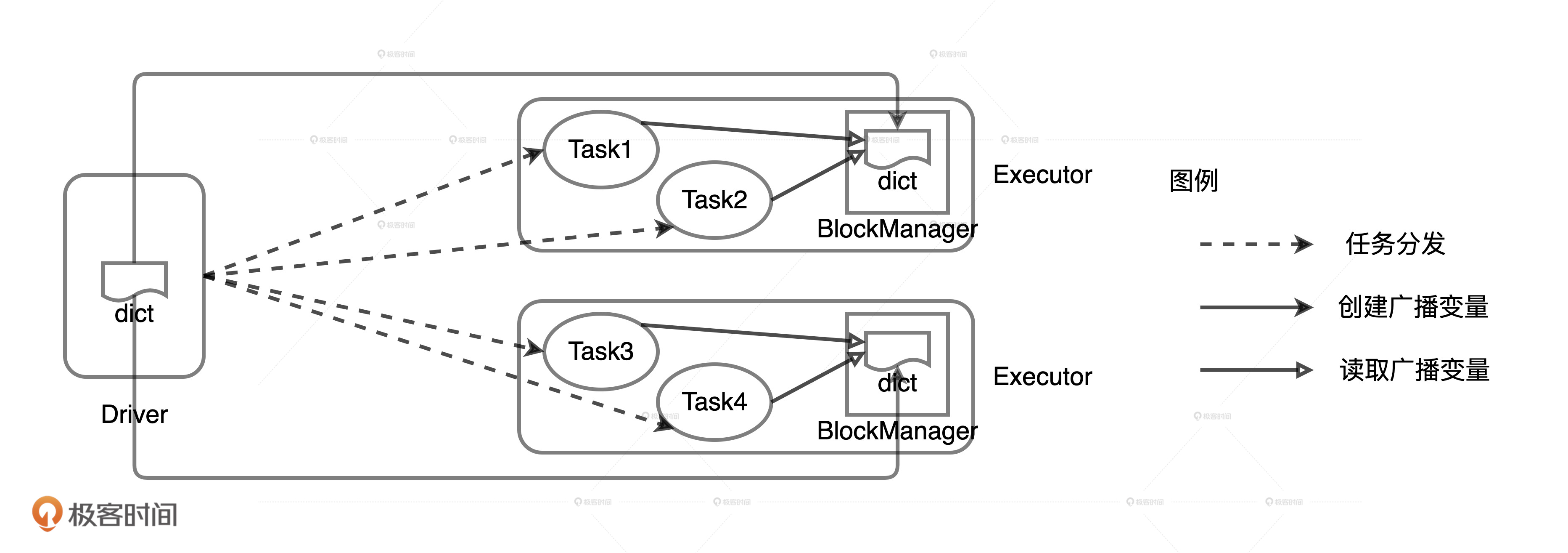
使用广播变量
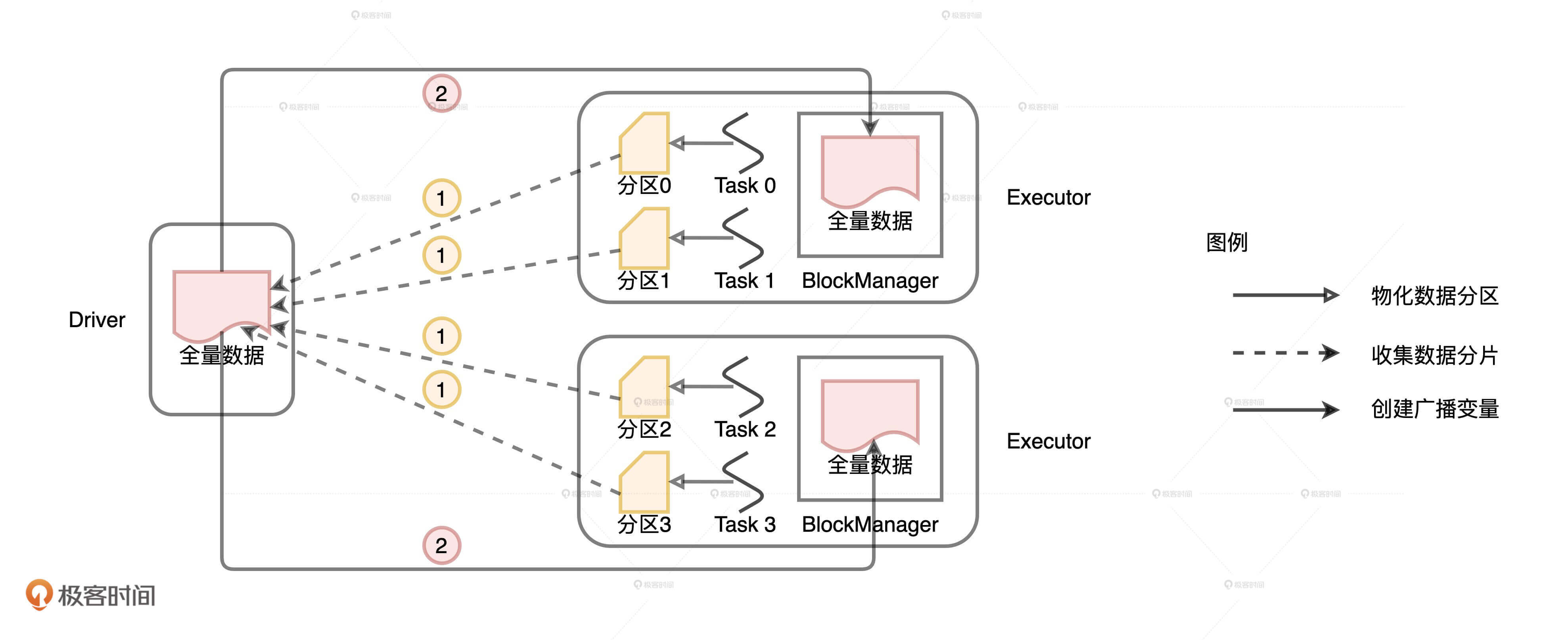
与普通变量相比,分布式数据集的数据源不在 Driver 端,而是来自所有的 Executors。Executors 中的每个分布式任务负责生产全量数据集的一部分,也就是图中不同的数据分区。因此,步骤 1 就是 Driver 从所有的 Executors 拉取这些数据分区,然后在本地构建全量数据。步骤 2 与从普通变量创建广播变量的过程类似。 Driver 把汇总好的全量数据分发给各个 Executors,Executors 将接收到的全量数据缓存到存储系统的 BlockManager 中。
不难发现,相比从普通变量创建广播变量,从分布式数据集创建广播变量的网络开销更大。原因主要有二:一是,前者比后者多了一步网络通信;二是,前者的数据体量通常比后者大很多。
Driver 可能会成为瓶颈
改成由driver获取到数据分布,然后通知各个executor之间进行拉取,这样可以利用多个executor网络,避免只有driver组装以后再一个一个发送效率过低
运用广播变量
spark.sql.autoBroadcastJoinThreshold 这个配置项。它的设置值是存储大小,默认是 10MB。它的含义是,对于参与 Join 的两张表来说,任意一张表的尺寸小于 10MB,Spark 就在运行时采用 Broadcast Joins 的实现方式去做数据关联。另外,AQE 在运行时尝试动态调整 Join 策略时,也是基于这个参数来判定过滤后的数据表是否足够小,从而把原本的 Shuffle Joins 调整为 Broadcast Joins。

预估一张表在内存中的存储大小
首先,我们要避开一个坑。我发现,有很多资料推荐用 Spark 内置的 SizeEstimator 去预估分布式数据集的存储大小。结合多次实战和踩坑经验,咱们必须要指出,SizeEstimator 的估算结果不准确。因此,你可以直接跳过这种方法,这也能节省你调优的时间和精力。
第一步,把要预估大小的数据表缓存到内存,比如直接在 DataFrame 或是 Dataset 上调用 cache 方法;第二步,读取 Spark SQL 执行计划的统计数据。这是因为,Spark SQL 在运行时,就是靠这些统计数据来制定和调整执行策略的。
1 | sval df: DataFrame = _ |
用 Join Hints 强制广播
1 | val table1: DataFrame = spark.read.parquet(path1) |
用 broadcast 函数强制广播
1 | import org.apache.spark.sql.functions.broadcast |
总结
我认为,以广播阈值配置为主,以强制广播为辅,往往是不错的选择。
广播阈值的设置,更多的是把选择权交给 Spark SQL,尤其是在 AQE 的机制下,动态 Join 策略调整需要这样的设置在运行时做出选择。强制广播更多的是开发者以专家经验去指导 Spark SQL 该如何选择运行时策略。二者相辅相成,并不冲突,开发者灵活地运用就能平衡 Spark SQL 优化策略与专家经验在应用中的比例。
首先,从性能上来讲,Driver 在创建广播变量的过程中,需要拉取分布式数据集所有的数据分片。在这个过程中,网络开销和 Driver 内存会成为性能隐患。广播变量尺寸越大,额外引入的性能开销就会越多。更何况,如果广播变量大小超过 8GB,Spark 会直接抛异常中断任务执行。
其次,从功能上来讲,并不是所有的 Joins 类型都可以转换为 Broadcast Joins。一来,Broadcast Joins 不支持全连接(Full Outer Joins);二来,在所有的数据关联中,我们不能广播基表。或者说,即便开发者强制广播基表,也无济于事。比如说,在左连接(Left Outer Join)中,我们只能广播右表;在右连接(Right Outer Join)中,我们只能广播左表。在下面的代码中,即便我们强制用 broadcast 函数进行广播,Spark SQL 在运行时还是会选择 Shuffle Joins。
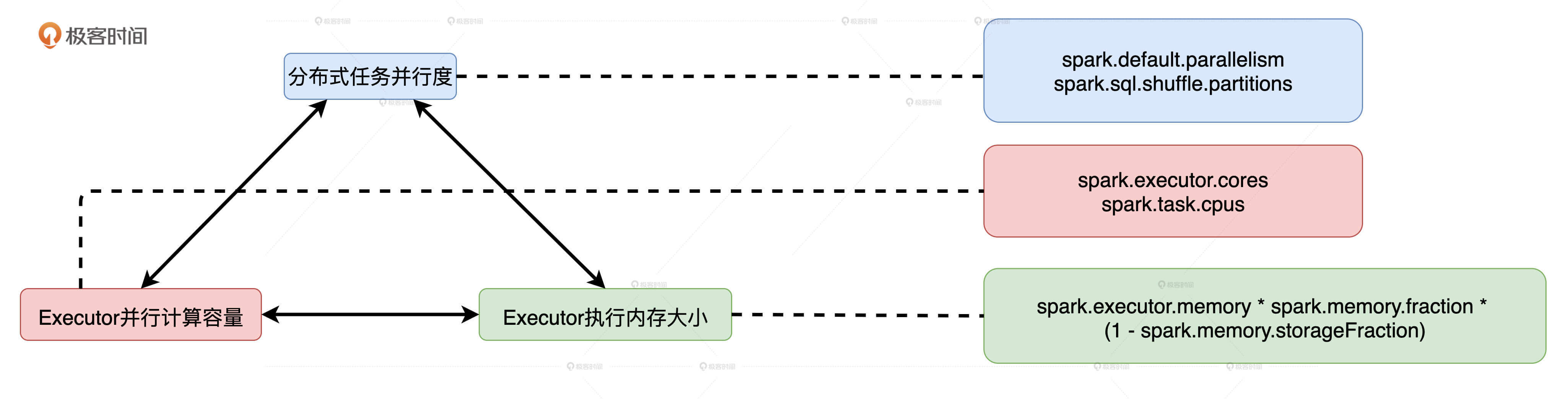
并行度、并发度与执行内存
并行度
并行度指的是为了实现分布式计算,分布式数据集被划分出来的份数。并行度明确了数据划分的粒度:并行度越高,数据的粒度越细,数据分片越多,数据越分散。
并行度可以通过两个参数来设置,分别是 spark.default.parallelism 和 spark.sql.shuffle.partitions。前者用于设置 RDD 的默认并行度,后者在 Spark SQL 开发框架下,指定了 Shuffle Reduce 阶段默认的并行度。
并发度
Executor 的线程池大小由参数 spark.executor.cores 决定,每个任务在执行期间需要消耗的线程数由 spark.task.cpus 配置项给定。两者相除得到的商就是并发度,也就是同一时间内,一个 Executor 内部可以同时运行的最大任务数量。又因为,spark.task.cpus 默认数值为 1,并且通常不需要调整,所以,并发度基本由 spark.executor.cores 参数敲定。
就 Executor 的线程池来说,尽管线程本身可以复用,但每个线程在同一时间只能计算一个任务,每个任务负责处理一个数据分片。因此,在运行时,线程、任务与分区是一一对应的关系。
CPU 低效原因之一:线程挂起
在给定执行内存总量 M 和线程总数 N 的情况下,为了保证每个线程都有机会拿到适量的内存去处理数据,Spark 用 HashMap 数据结构,以(Key,Value)的方式来记录每个线程消耗的内存大小,并确保所有的 Value 值都不超过 M/N。在一些极端情况下,有些线程申请不到所需的内存空间,能拿到的内存合计还不到 M/N/2。这个时候,Spark 就会把线程挂起,直到其他线程释放了足够的内存空间为止。
我们之前把每个 Task 需要处理的数据分片比作是作物种子,那么,数据分片的数据量决定了执行任务需要申请多少内存。如果分布式数据集的并行度设置得当,因任务调度滞后而导致的线程挂起问题就会得到缓解。
CPU 低效原因之二:调度开销
当然不是,并行度足够大,确实会让数据分片更分散、数据粒度更细,因此,每个执行任务所需消耗的内存更少。但是,数据过于分散会带来严重的副作用:调度开销骤增。
对于每一个分布式任务,Dirver 会将其封装为 TaskDescription,然后分发给各个 Executor。TaskDescription 包含着与任务运行有关的所有信息,如任务 ID、尝试 ID、要处理的数据分片 ID、开发者添加的本地文件和 Jar 包、任务属性、序列化的任务代码等等。Executor 接收到 TaskDescription 之后,首先需要对 TaskDescription 反序列化才能读取任务信息,然后将任务代码再反序列化得到可执行代码,最后再结合其他任务信息创建 TaskRunner。
因此你看,每个任务的调度与执行都需要 Executor 消耗 CPU 去执行上述一系列的操作步骤。数据分片与线程、执行任务一一对应,当数据过于分散,分布式任务数量会大幅增加,但每个任务需要处理的数据量却少之又少,就 CPU 消耗来说,相比花在数据处理上的比例,任务调度上的开销几乎与之分庭抗礼。显然,在这种情况下,CPU 的有效利用率也是极低的。
如何优化 CPU 利用率
因此,在给定 Executor 线程池和执行内存大小的时候,我们可以参考上面的算法,去计算一个能够让数据分片平均大小在(M/N/2, M/N)之间的并行度,这往往是个不错的选择。
存储空间视角
缓存RDD的过程
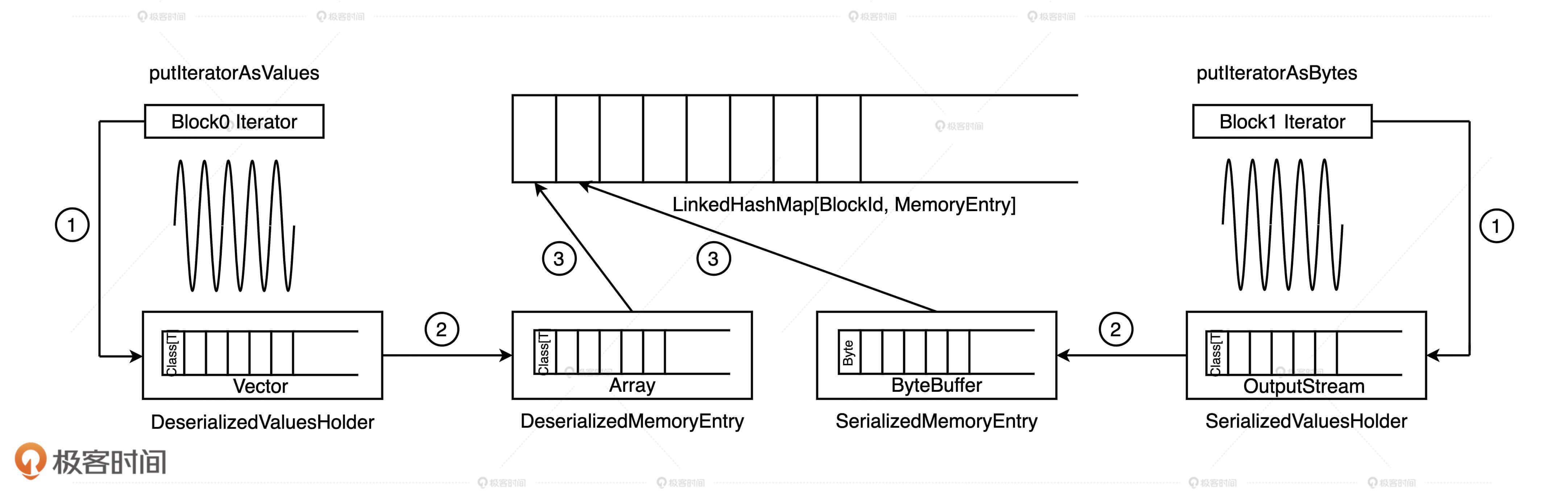
- 第一步就是通过调用 putIteratorAsValues 或是 putIteratorAsBytes 方法,把 RDD 迭代器展开为数据值,然后把这些数据值暂存到一个叫做 ValuesHolder 的数据结构里。这一步,我们通常把它叫做“Unroll”。
- 第二步,为了节省内存开销,我们可以在存储数据值的 ValuesHolder 上直接调用 toArray 或是 toByteBuffer 操作,把 ValuesHolder 转换为 MemoryEntry 数据结构。
- 第三步,这些包含 RDD 数据值的 MemoryEntry 和与之对应的 BlockId,会被一起存入 Key 为 BlockId、Value 是 MemoryEntry 引用的链式哈希字典中。因此,LinkedHashMap[BlockId, MemoryEntry]缓存的是关于数据存储的元数据,MemoryEntry 才是真正保存 RDD 数据实体的存储单元。换句话说,大面积占用内存的不是哈希字典,而是一个又一个的 MemoryEntry。
透过 Shuffle 看 DiskStore
DiskStore 中数据的存取本质上就是字节序列与磁盘文件之间的转换,它通过 putBytes 方法把字节序列存入磁盘文件,再通过 getBytes 方法将文件内容转换为数据块。
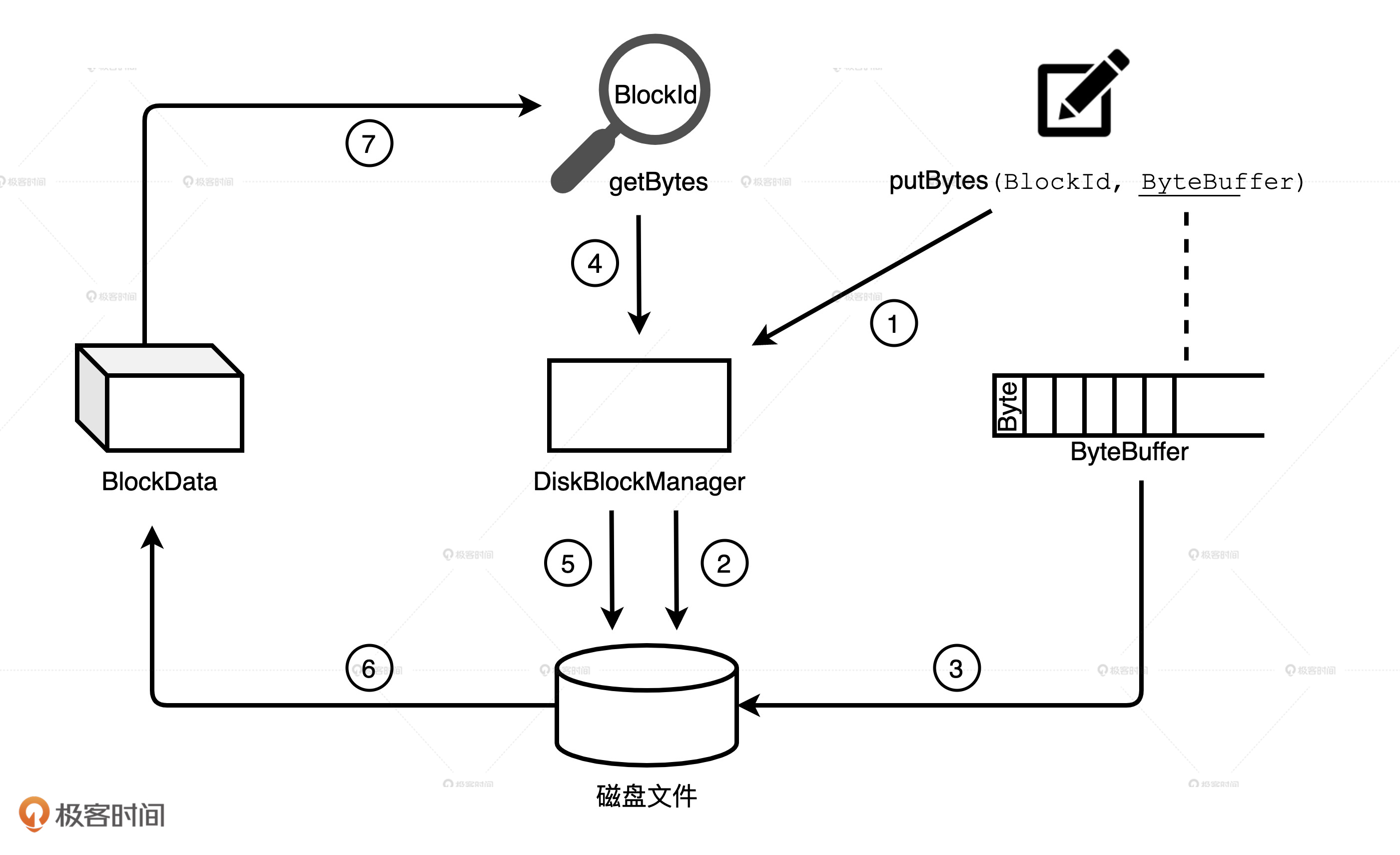
DiskStore 这个狡猾的家伙并没有亲自维护这些元数据,而是请了 DiskBlockManager 这个给力的帮手。
DiskBlockManager 的主要职责就是,记录逻辑数据块 Block 与磁盘文件系统中物理文件的对应关系,每个 Block 都对应一个磁盘文件。
如何有效避免Cache滥用
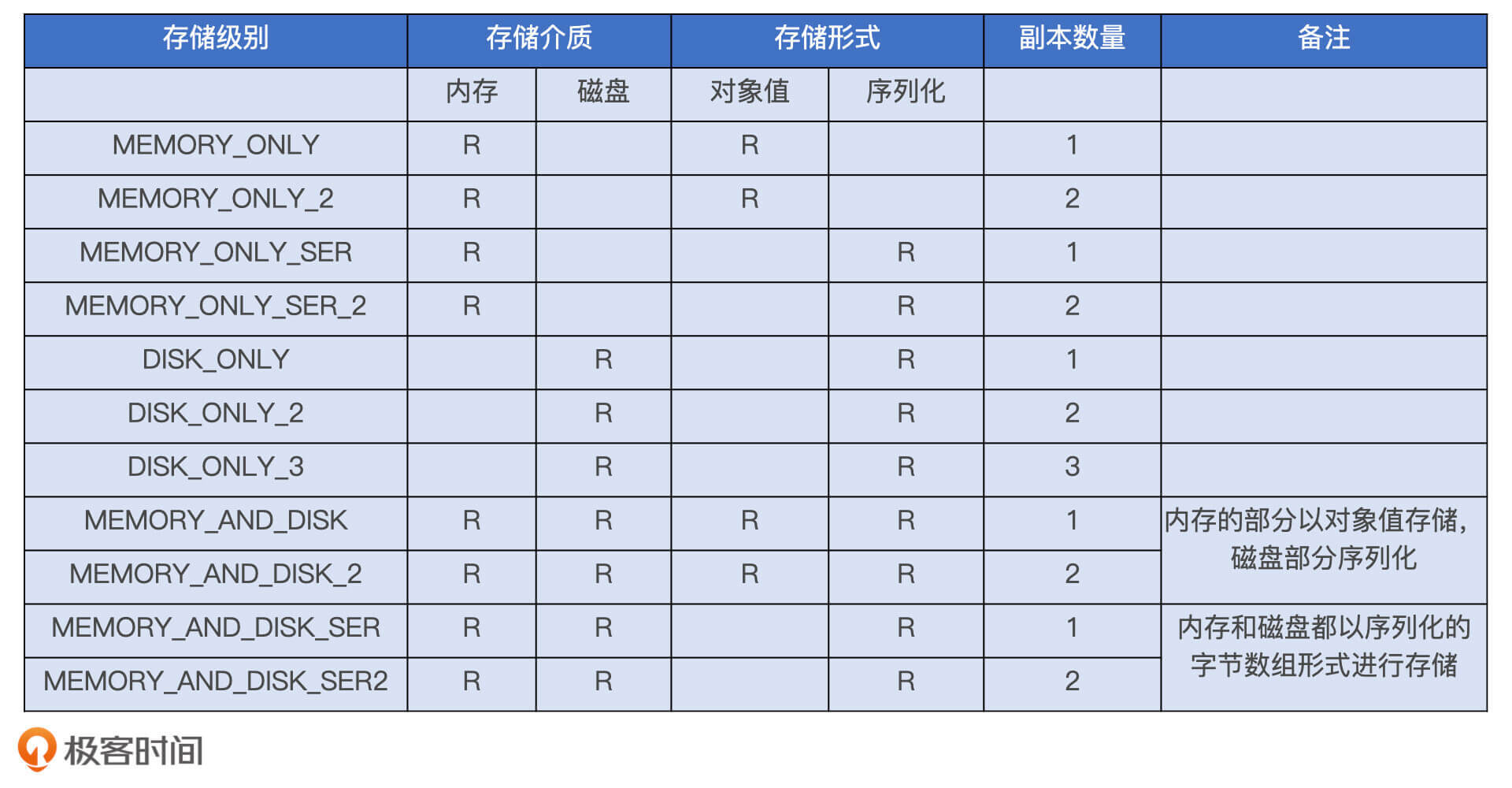
存储级别
每一种存储级别都包含 3 个基本要素。
- 存储介质:内存还是磁盘,或是两者都有。
- 存储形式:对象值还是序列化的字节数组,带 SER 字样的表示以序列化方式存储,不带 SER 则表示采用对象值。
- 副本数量:存储级别名字最后的数字代表拷贝数量,没有数字默认为 1 份副本。
缓存的销毁过程
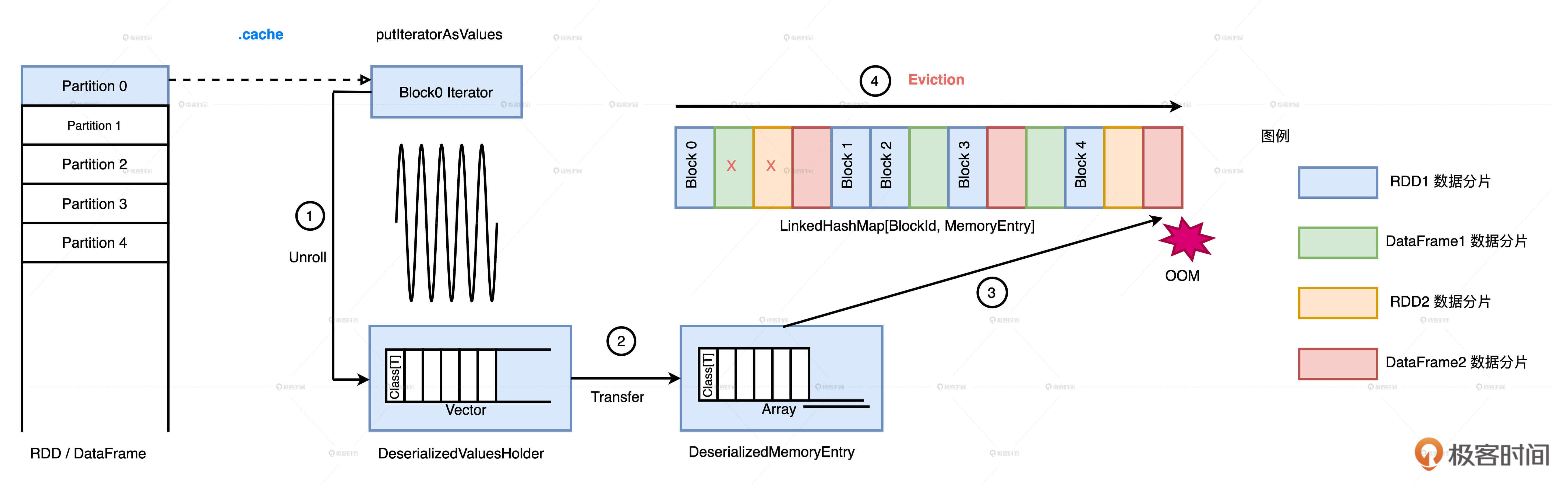
我们用一张图来演示这个过程,假设 MemoryStore 中存有 4 个 RDD/Data Frame 的缓存数据,这 4 个分布式数据集各自缓存了一些数据分片之后,Storage Memory 区域就被占满了。当 RDD1 尝试把第 6 个分片缓存到 MemoryStore 时,却发现内存不足,塞不进去了。
这种情况下,Spark 就会逐一清除一些“尸位素餐”的 MemoryEntry 来释放内存,从而获取更多的可用空间来存储新的数据分片。这个过程叫做 Eviction,它的中文翻译还是蛮形象的,就叫做驱逐,也就是把 MemoryStore 中那些倒霉的 MemoryEntry 驱逐出内存。
在清除缓存的过程中,Spark 遵循两个基本原则:
- LRU:按照元素的访问顺序,优先清除那些“最近最少访问”的 BlockId、MemoryEntry 键值对
- 兔子不吃窝边草:在清除的过程中,同属一个 RDD 的 MemoryEntry 拥有“赦免权”
Spark 使用了一个巧妙的数据结构:LinkedHashMap,这种数据结构天然地支持 LRU 算法
定位OOM
Driver 端的 OOM
因此 Driver 端的 OOM 逃不出 2 类病灶:
- 创建的数据集超过内存上限
- 收集的结果集超过内存上限
比较难定位的是间接调用 collect 而导致的 OOM。那么,间接调用 collect 是指什么呢?还记得广播变量的工作原理吗?广播变量在创建的过程中,需要先把分布在所有 Executors 的数据分片拉取到 Driver 端,然后在 Driver 端构建广播变量,最后 Driver 端把封装好的广播变量再分发给各个 Executors。第一步的数据拉取其实就是用 collect 实现的。如果 Executors 中数据分片的总大小超过 Driver 端内存上限也会报 OOM。
1 | java.lang.OutOfMemoryError: Not enough memory to build and broadcast |
Executor 端的 OOM
在 Executors 中,与任务执行有关的内存区域才存在 OOM 的隐患。其中,Reserved Memory 大小固定为 300MB,因为它是硬编码到源码中的,所以不受用户控制。而对于 Storage Memory 来说,即便数据集不能完全缓存到 MemoryStore,Spark 也不会抛 OOM 异常,额外的数据要么落盘(MEMORY_AND_DISK)、要么直接放弃(MEMORY_ONLY)。
Execution Memory 的 OOM
一旦分布式任务的内存请求超出 1/N 这个上限,Execution Memory 就会出现 OOM 问题。
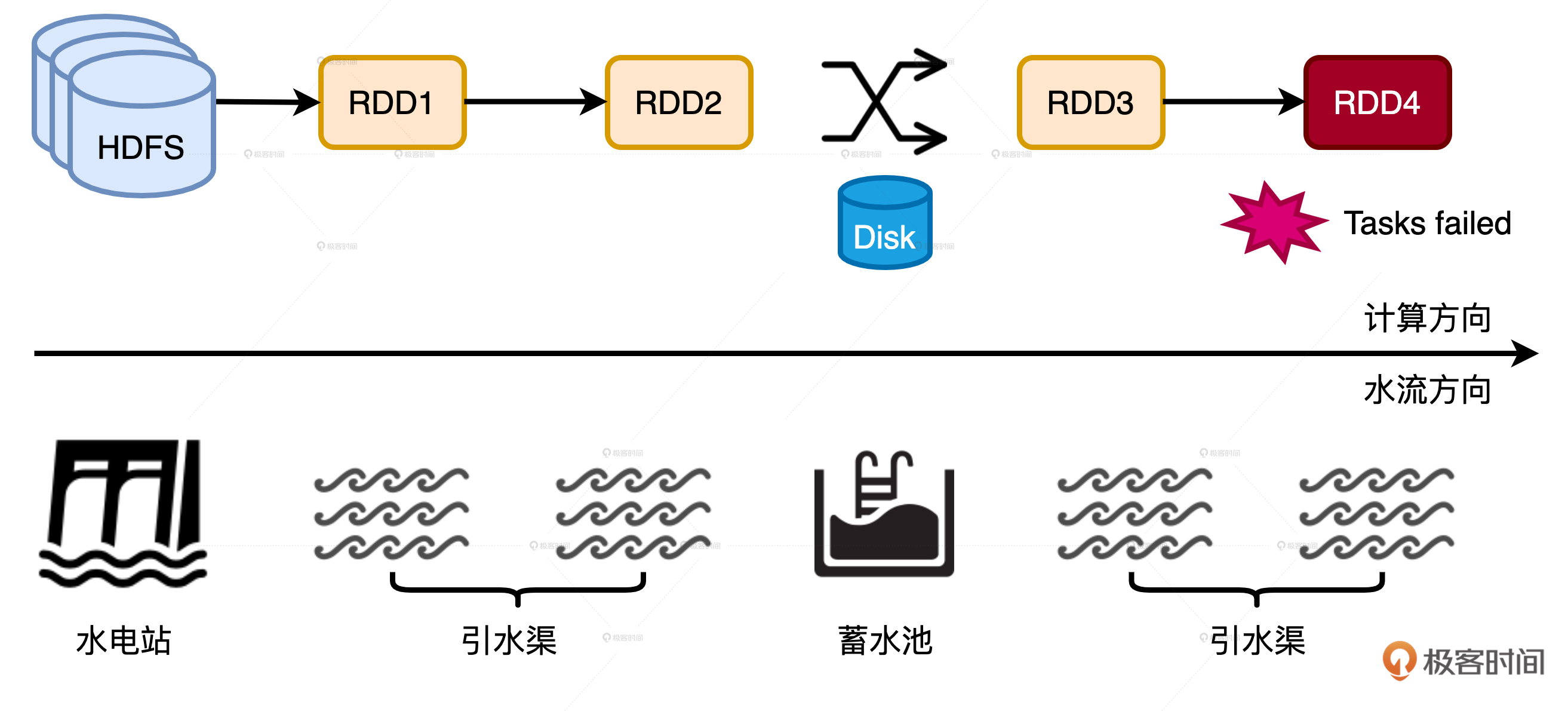
磁盘在功能上的作用
- 磁盘在功能上的第一个作用:溢出临时文件
- 磁盘的在功能上的第二个作用:存储 Shuffle 中间文件。
- 磁盘的第三个作用就是缓存分布式数据集。也就是说,凡是带DISK字样的存储模式,都会把内存中放不下的数据缓存到磁盘。
性能上的价值
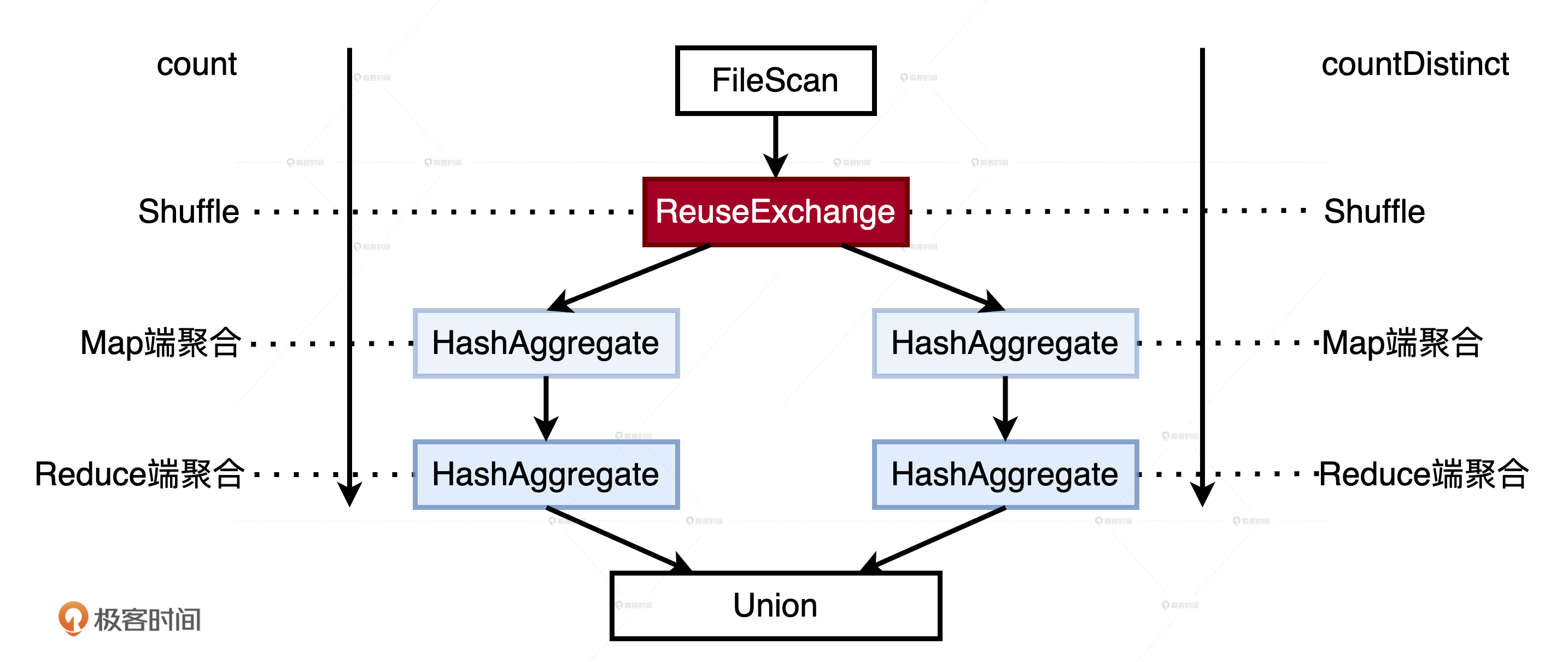
磁盘复用,它指的是 Shuffle Write 阶段产生的中间文件被多次计算重复利用的过程。磁盘复用的收益之一就是缩短失败重试的路径,在保障作业稳定性的同时提升执行性能。
ReuseExchange 机制下的磁盘复用
ReuseExchange 是 Spark SQL 众多优化策略中的一种,它指的是相同或是相似的物理计划可以共享 Shuffle 计算的中间结果,也就是我们常说的 Shuffle 中间文件。ReuseExchange 机制可以帮我们削减 I/O 开销,甚至节省 Shuffle,来大幅提升执行性能。
事实上,触发条件至少有 2 个:
- 多个查询所依赖的分区规则要与 Shuffle 中间数据的分区规则保持一致
- 多个查询所涉及的字段(Attributes)要保持一致
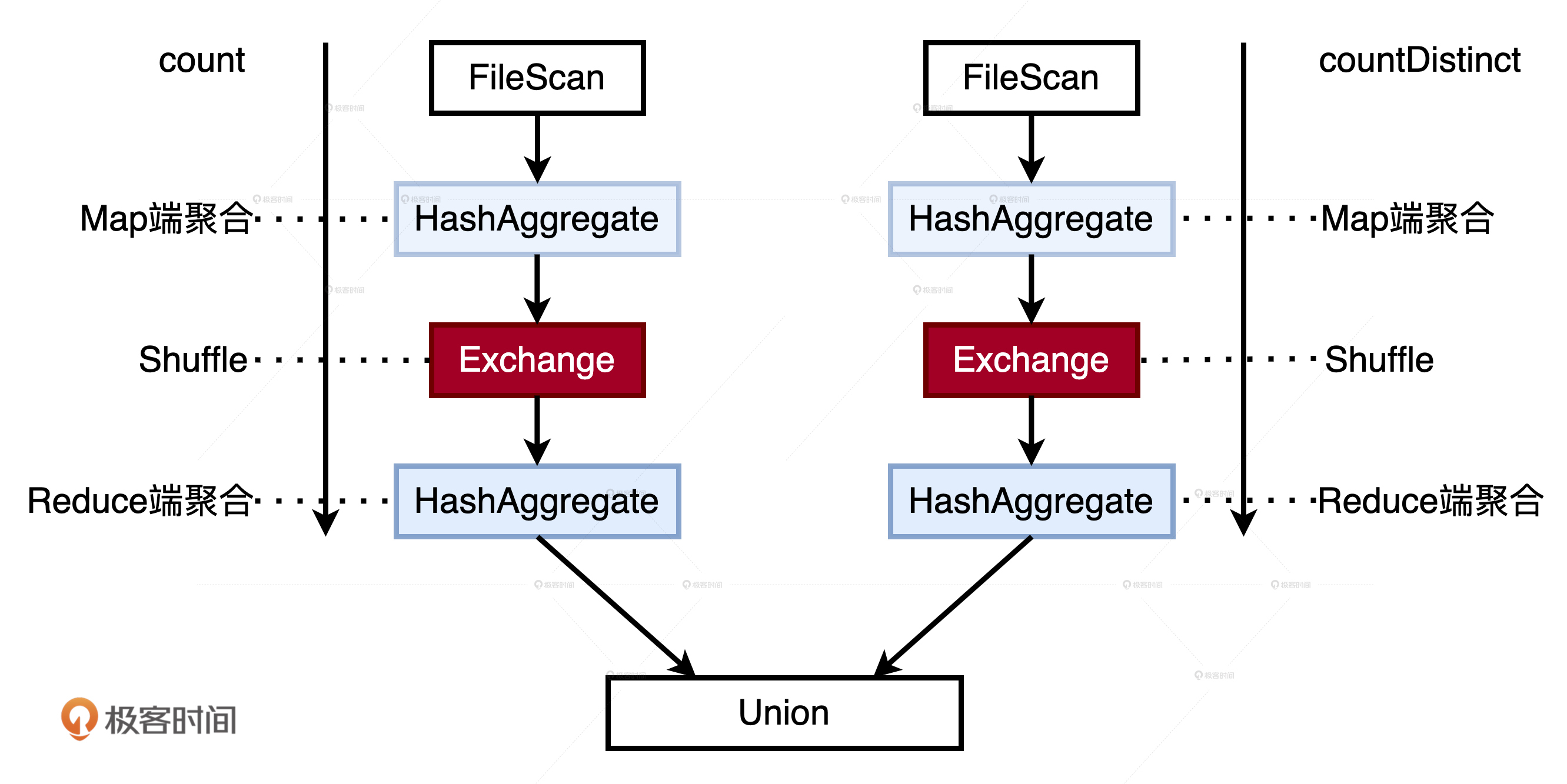
优化前
1 | //版本1:分别计算PV、UV,然后合并 |
优化后
1 | //版本2:分别计算PV、UV,然后合并 |
数据传输
在 Spark 中,有两种序列化器供开发者选择,分别是 Java serializer 和 Kryo Serializer。Spark 官方和网上的技术博客都会推荐你使用 Kryo Serializer 来提高效率。
对于一些自定义的数据结构来说,如果你没有明确把这些类型向 Kryo Serializer 注册的话,虽然它依然会帮你做序列化的工作,但它序列化的每一条数据记录都会带一个类名字,这个类名字是通过反射机制得到的,会非常长。在上亿的样本中,存储开销自然相当可观。
我们只需要在 SparkConf 之上调用 registerKryoClasses 方法就好了。
SparkSql性能调优

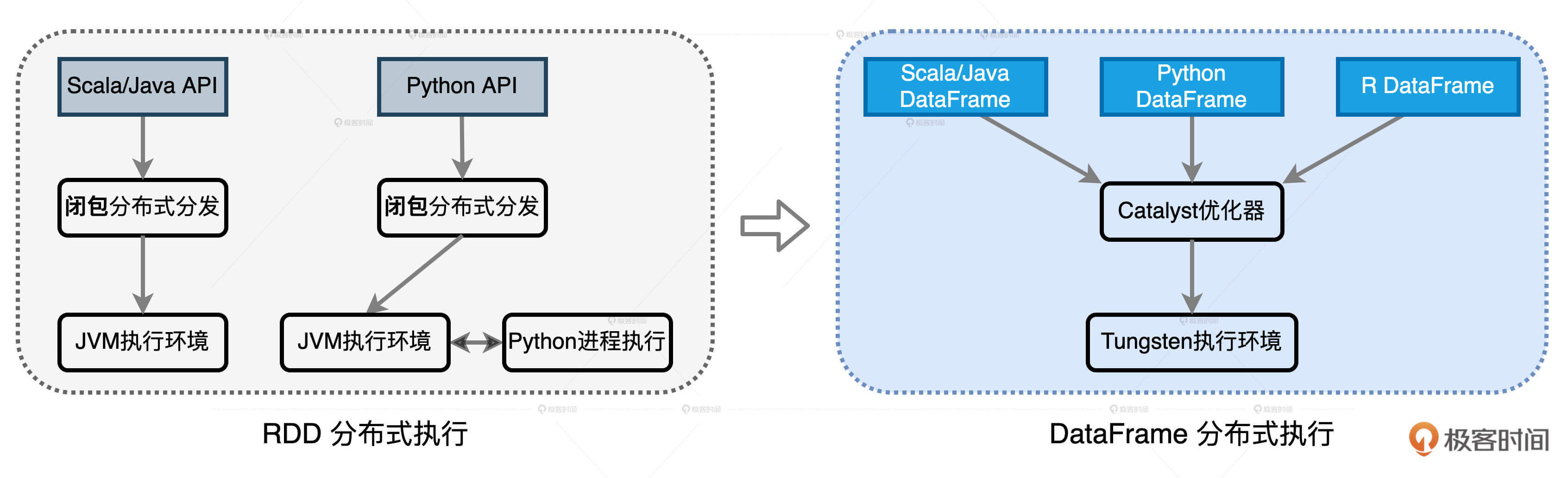
Catalyst逻辑计划
Catalyst 逻辑优化阶段分为两个环节:逻辑计划解析和逻辑计划优化。在逻辑计划解析中,Catalyst 把“Unresolved Logical Plan”转换为“Analyzed Logical Plan”;在逻辑计划优化中,Catalyst 基于一些既定的启发式规则(Heuristics Based Rules),把“Analyzed Logical Plan”转换为“Optimized Logical Plan”。
dsl
1 | val userFile: String = _ |
Unresolved Logical Plan

Analyzed Logical Plan

Optimized Logical Plan

Catalyst 的优化规则
可以归纳到以下 3 个范畴:
- 谓词下推(Predicate Pushdown)
- 列剪裁(Column Pruning)
- 常量替换 (Constant Folding)
Cache Manager 优化
从“Analyzed Logical Plan”到“Optimized Logical Plan”的转换,Catalyst 除了使用启发式的规则以外,还会利用 Cache Manager 做进一步的优化。
这里的 Cache 指的就是我们常说的分布式数据缓存。想要对数据进行缓存,你可以调用 DataFrame 的.cache 或.persist,或是在 SQL 语句中使用“cache table”关键字。
当 Catalyst 尝试对逻辑计划做优化时,会先尝试对 Cache Manager 查找,看看当前的逻辑计划或是逻辑计划分支,是否已经被记录在 Cache Manager 的字典里。如果在字典中可以查到当前计划或是分支,Catalyst 就用 InMemoryRelation 节点来替换整个计划或是计划的一部分,从而充分利用已有的缓存数据做优化。
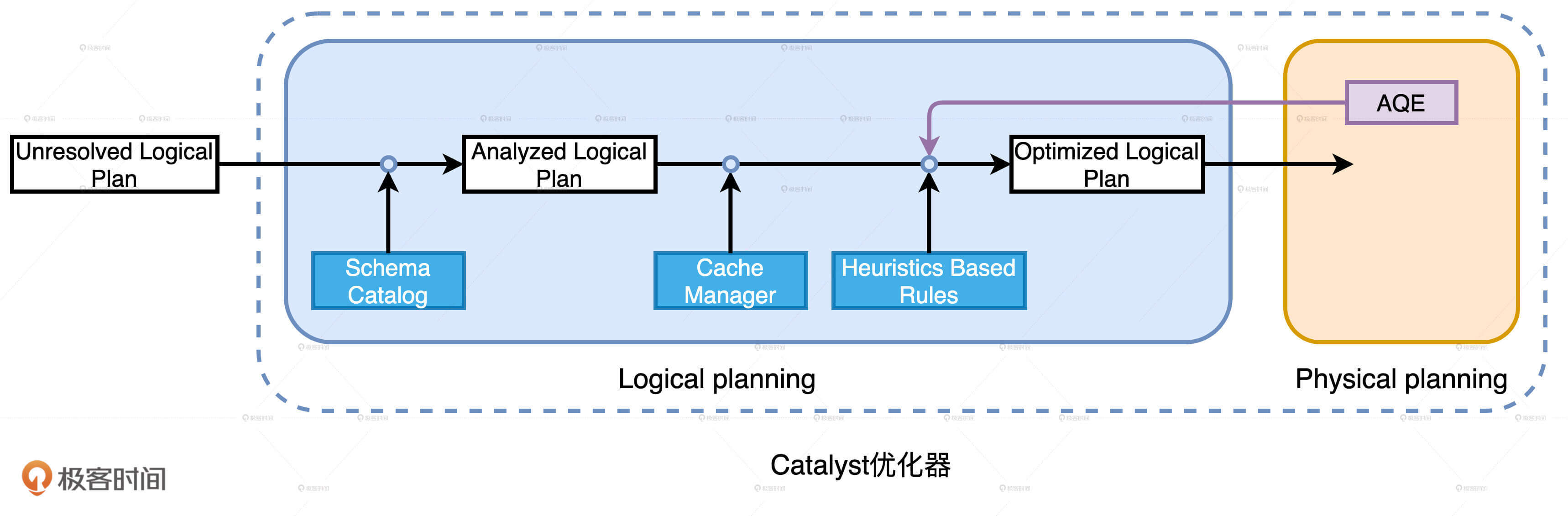
Catalyst物理计划
为了把逻辑计划交付执行,Catalyst 还需要把 Optimized Logical Plan 转换为物理计划。物理计划比逻辑计划更具体,它明确交代了 Spark SQL 的每一步具体该怎么执行。
为了让查询计划(Query Plan)变得可操作、可执行,Catalyst 的物理优化阶段(Physical Planning)可以分为两个环节:优化 Spark Plan 和生成 Physical Plan。
- 在优化 Spark Plan 的过程中,Catalyst 基于既定的优化策略(Strategies),把逻辑计划中的关系操作符一一映射成物理操作符,生成 Spark Plan。
- 在生成 Physical Plan 过程中,Catalyst 再基于事先定义的 Preparation Rules,对 Spark Plan 做进一步的完善、生成可执行的 Physical Plan。
优化 Spark Plan

从 Optimized Logical Plan 摇身一变,转换成了 Spark Plan,也明确了在运行时采用 SMJ 来做关联计算。不过,即使小 Q 在 Spark Plan 中已经明确了每一步该“怎么做”,但是,Spark 还是做不到把这样的查询计划转化成可执行的分布式任务。
生成 Physical Plan

现 Physical Plan 中多了很多星号“”,这些星号的后面还带着括号和数字,如图中的“(3)”、“(1)”。这种星号“”标记表示的就是 WSCG,后面的数字代表 Stage 编号。因此,括号中数字相同的操作,最终都会被捏合成一份“手写代码”,也就是我们下一讲要说的 Tungsten 的 WSCG。
Shuffle Sort Merge Join 的计算需要两个先决条件:Shuffle 和排序。而 Spark Plan 中并没有明确指定以哪个字段为基准进行 Shuffle,以及按照哪个字段去做排序。
因此,Catalyst 需要对 Spark Plan 做进一步的转换,生成可操作、可执行的 Physical Plan。
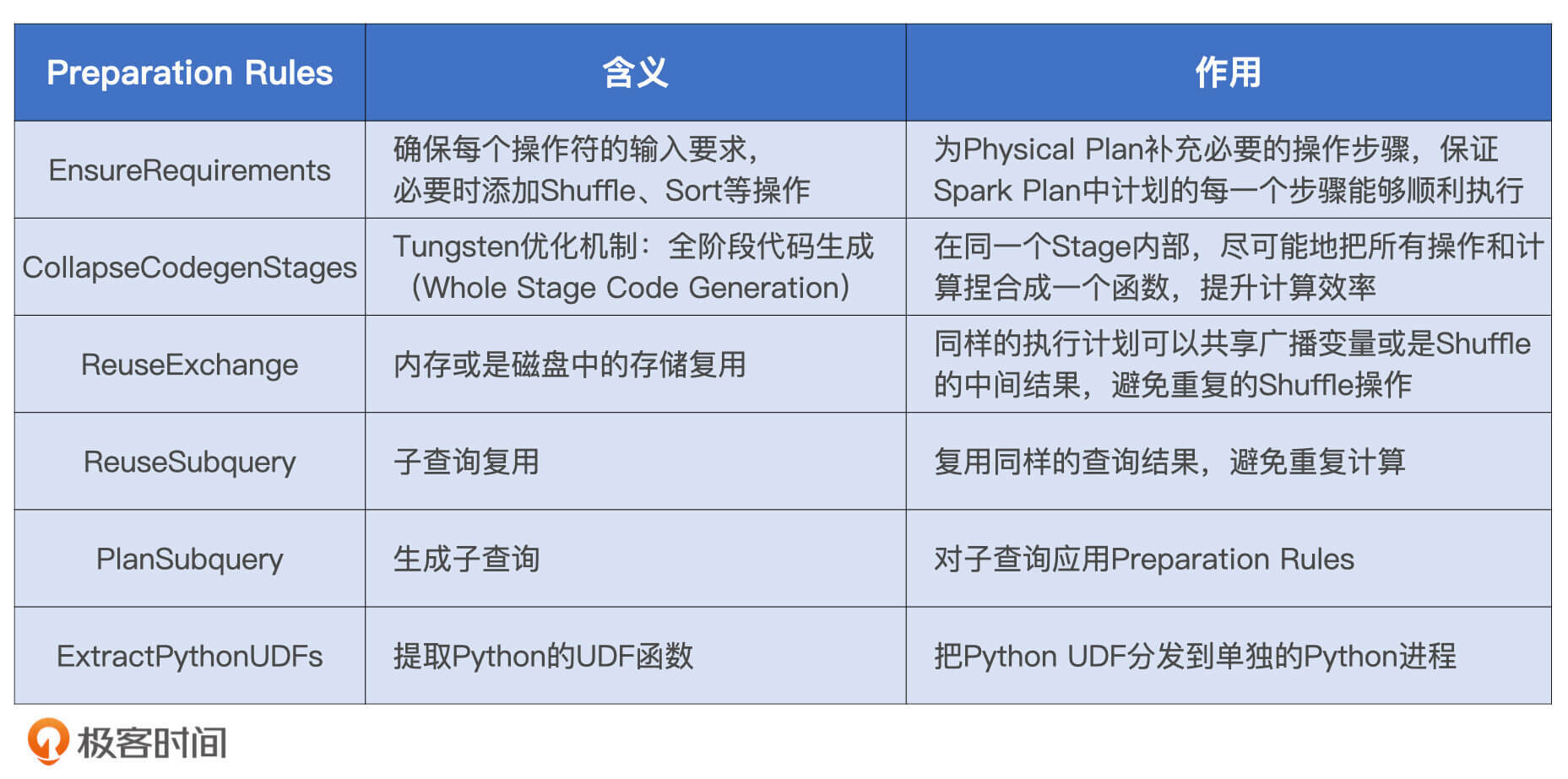
Preparation Rules 有 6 组规则,这些规则作用到 Spark Plan 之上就会生成 Physical Plan,而 Physical Plan 最终会由 Tungsten 转化为用于计算 RDD 的分布式任务。
EnsureRequirements 规则
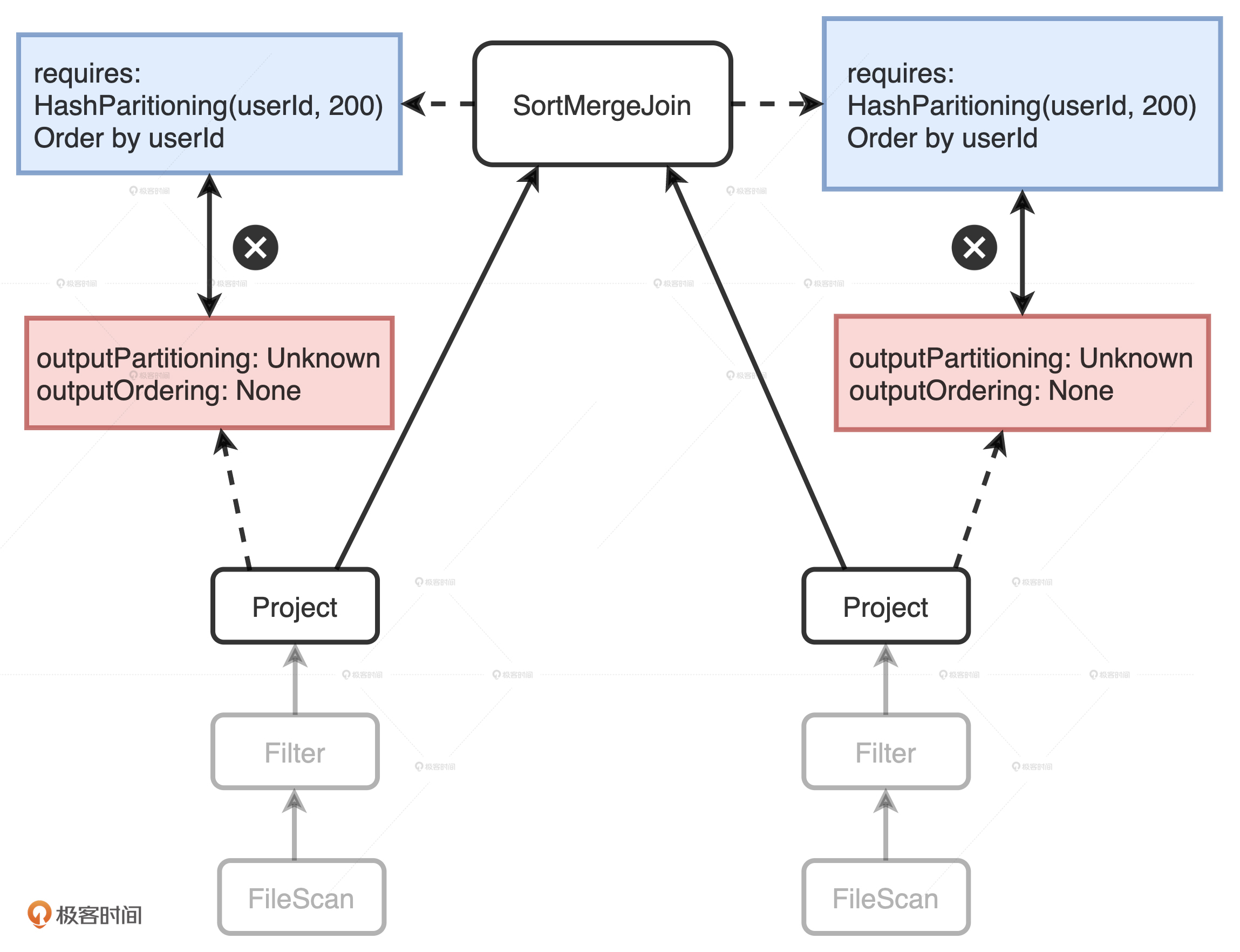
EnsureRequirements 翻译过来就是“确保满足前提条件”,这是什么意思呢?对于执行计划中的每一个操作符节点,都有 4 个属性用来分别描述数据输入和输出的分布状态。
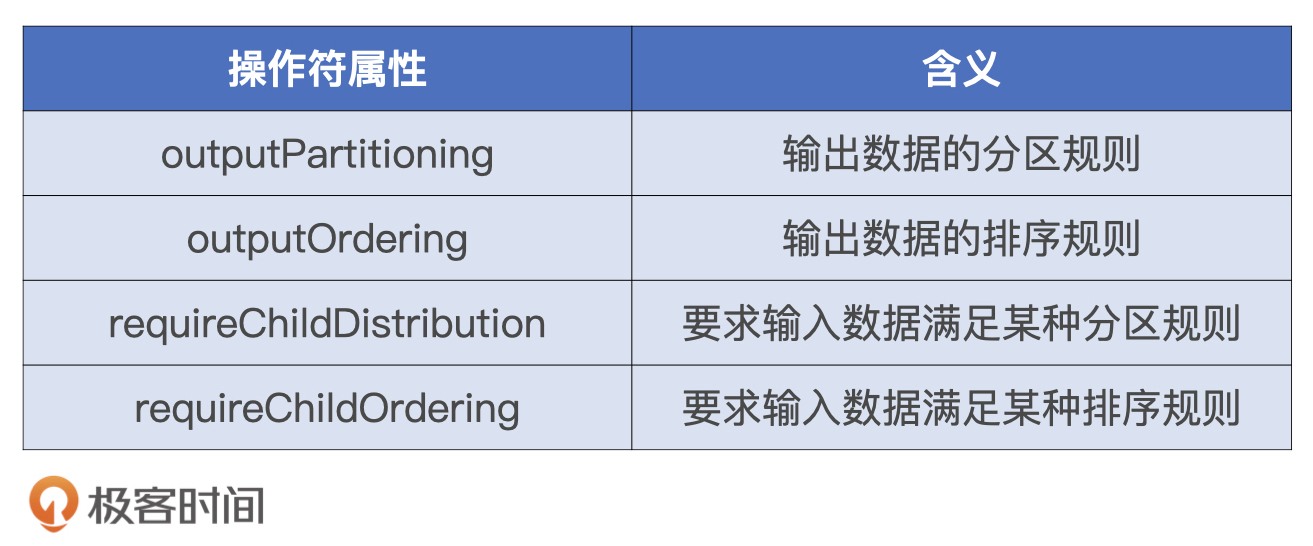
满足规则前
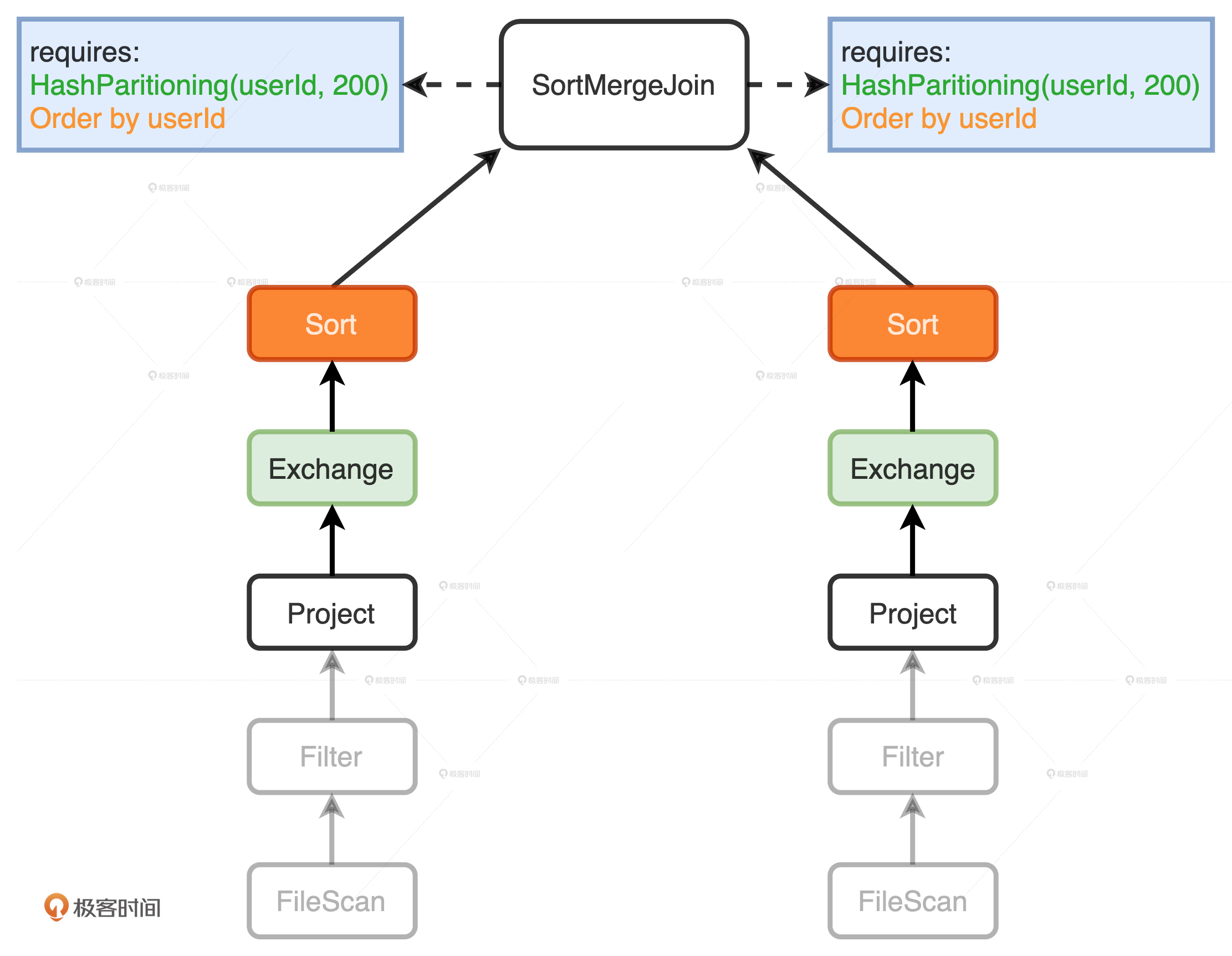
满足规则后
钨丝计划:Tungsten
Tungsten 又叫钨丝计划,它主要围绕内核引擎做了两方面的改进:数据结构设计和全阶段代码生成(WSCG,Whole Stage Code Generation)。
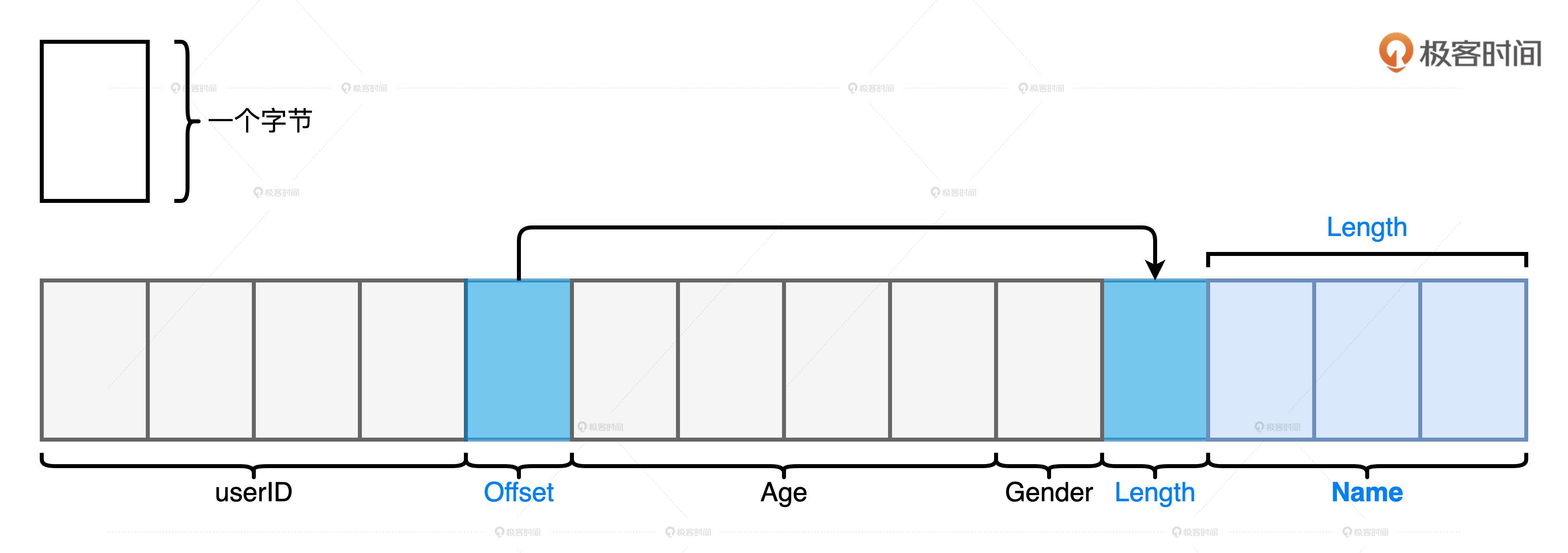
Unsafe Row:二进制数据结构
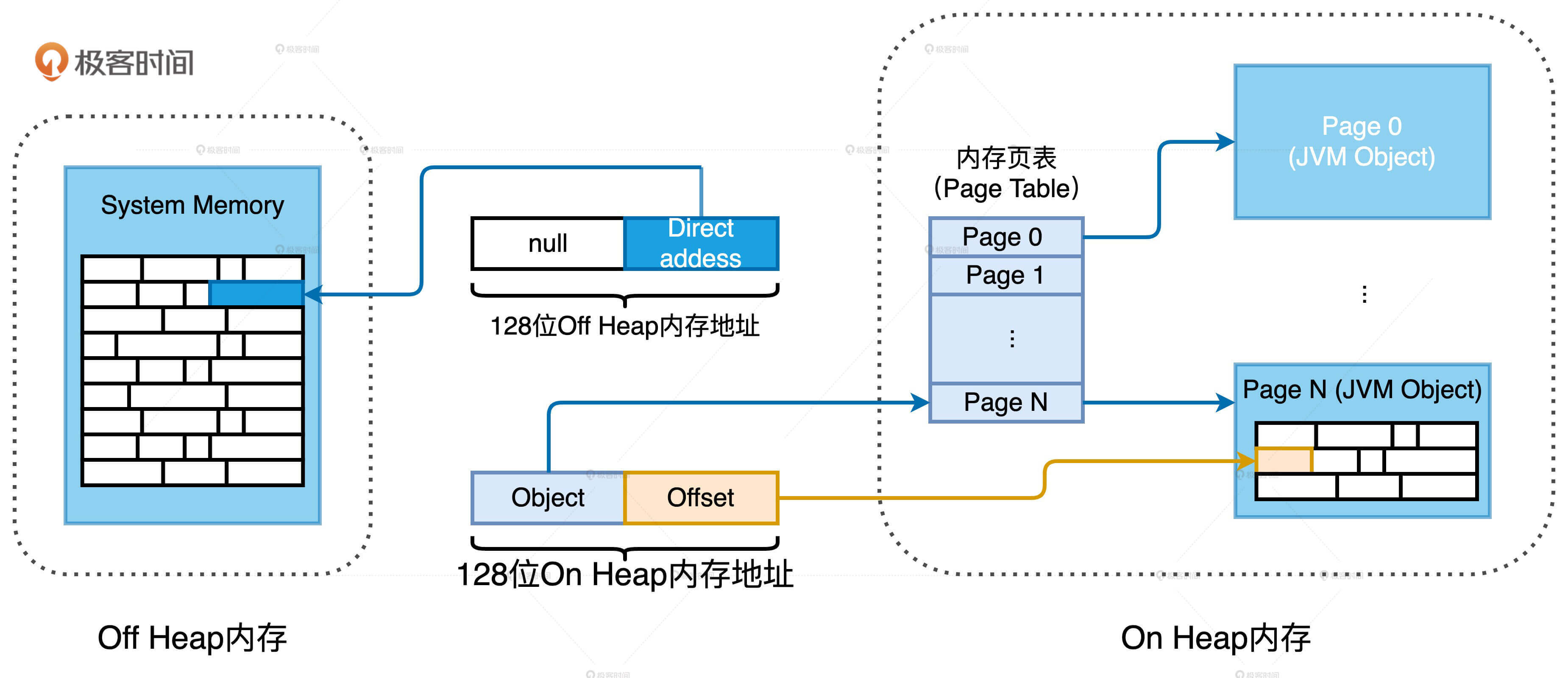
基于内存页的内存管理
为了统一管理 Off Heap 和 On Heap 内存空间,Tungsten 定义了统一的 128 位内存地址,简称 Tungsten 地址。Tungsten 地址分为两部分:前 64 位预留给 Java Object,后 64 位是偏移地址 Offset。但是,同样是 128 位的 Tungsten 地址,Off Heap 和 On Heap 两块内存空间在寻址方式上截然不同。
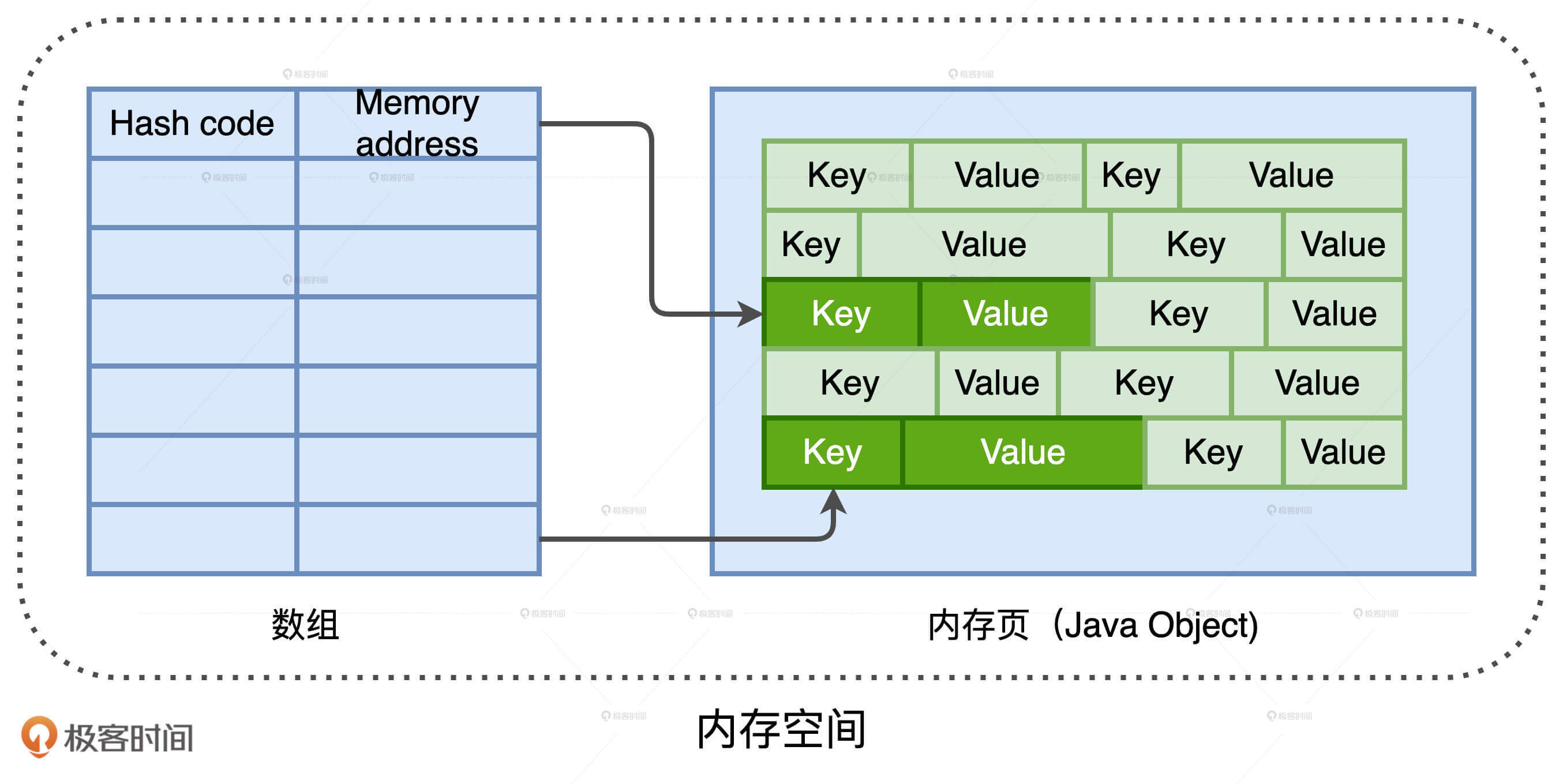
java.util.HashMap
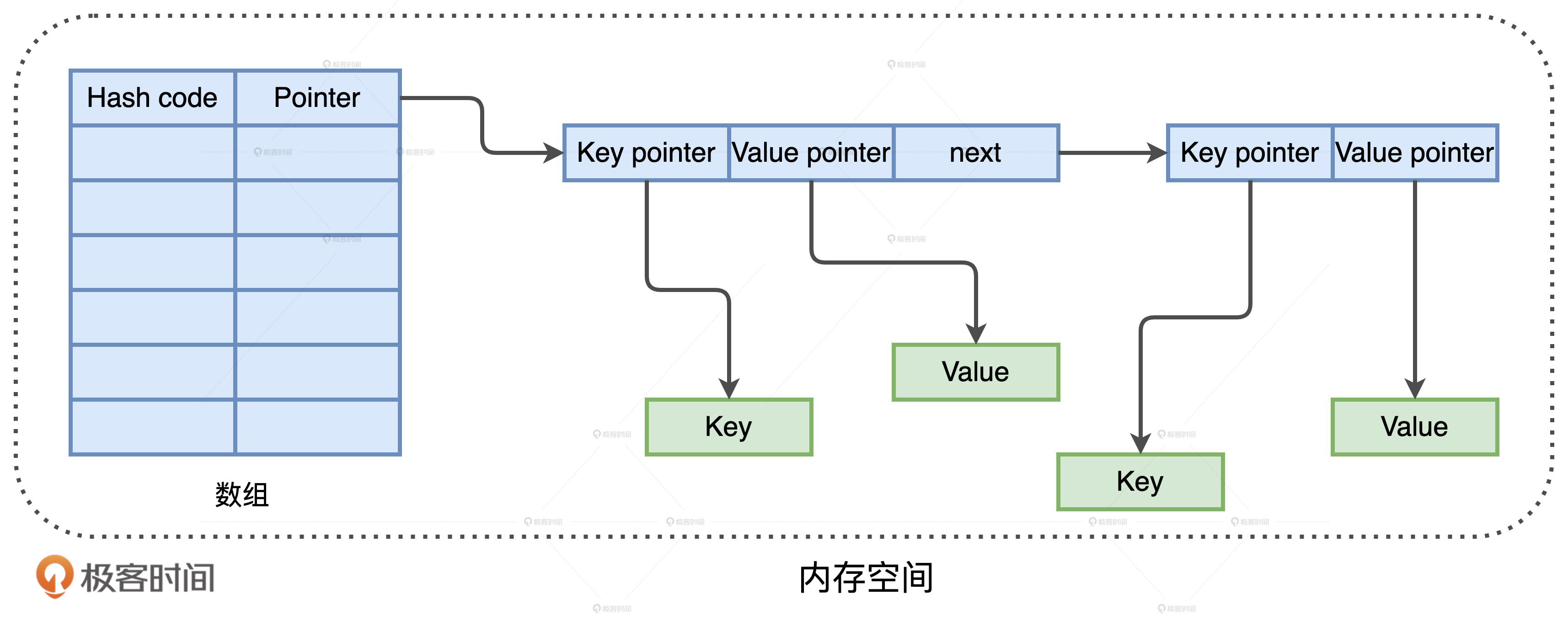
Tungsten HashMap
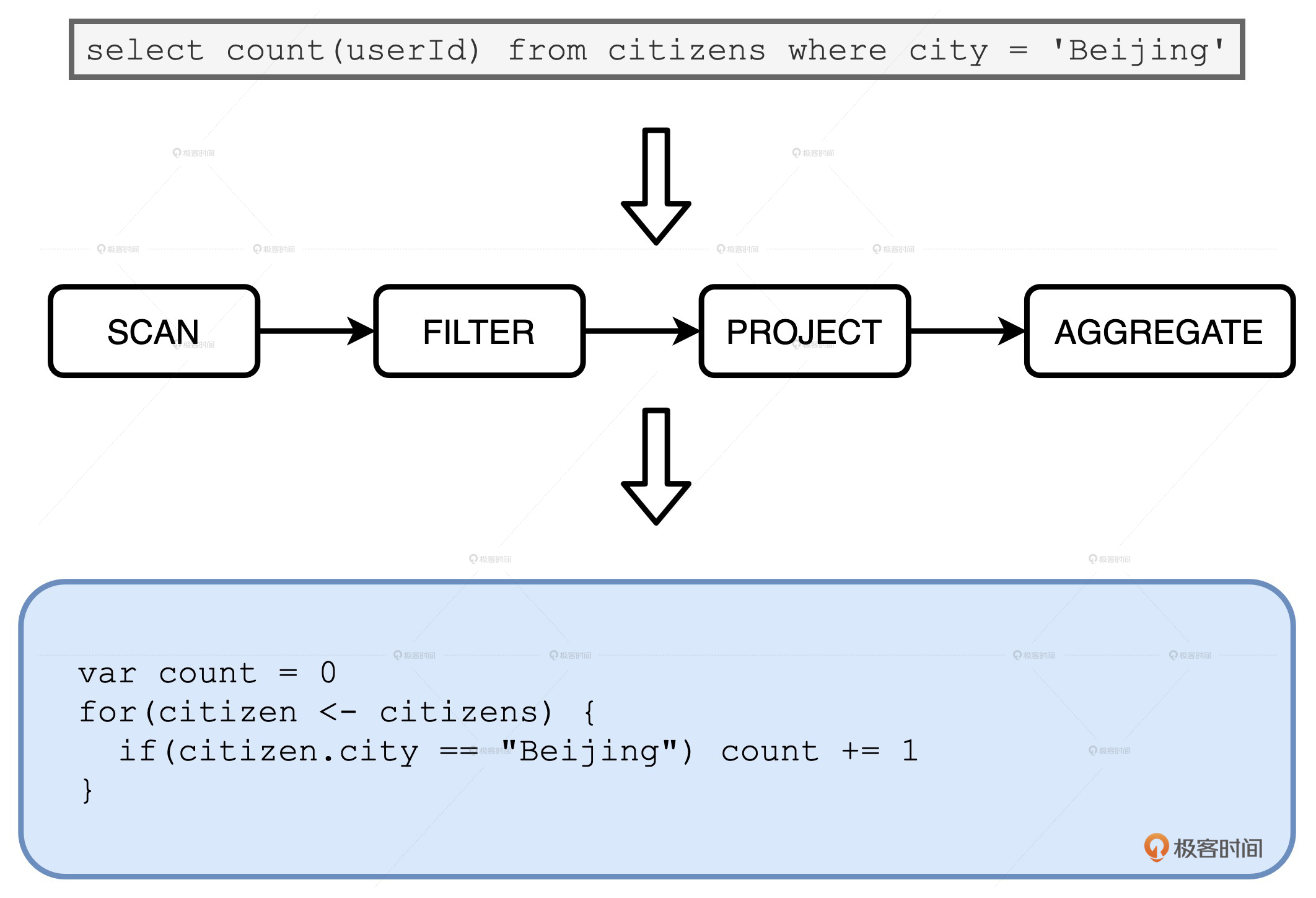
火山迭代模型
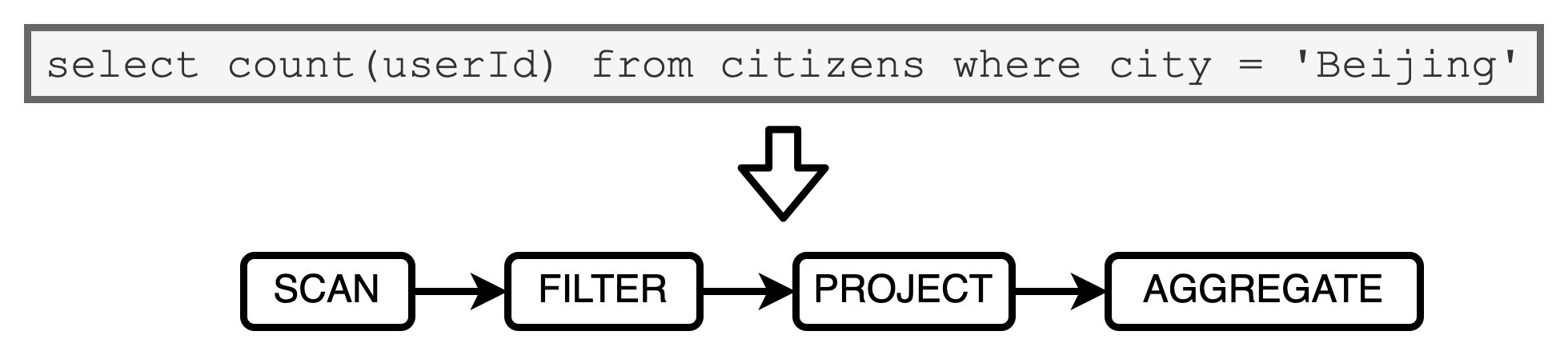
如果上面的查询使用 VI 模型去执行计算的话,都需要经过哪些步骤呢?对于数据源中的每条数据条目,语法树当中的每个操作符都需要完成如下步骤:
- 从内存中读取父操作符的输出结果作为输入数据
- 调用 hasNext、next 方法,以操作符逻辑处理数据,如过滤、投影、聚合等等
- 将处理后的结果以统一的标准形式输出到内存,供下游算子消费
WSCG
WSCG 指的是基于同一 Stage 内操作符之间的调用关系,生成一份“手写代码”,真正把所有计算融合为一个统一的函数。
Spark Plan 在转换成 Physical Plan 之前,会应用一系列的 Preparation Rules。这其中很重要的一环就是 CollapseCodegenStages 规则,它的作用正是尝试为每一个 Stages 生成“手写代码”。
总的来说,手写代码的生成过程分为两个步骤:
- 从父节点到子节点,递归调用 doProduce,生成代码框架从子节点到父节点,递归
- 调用 doConsume,向框架填充每一个操作符的运算逻辑
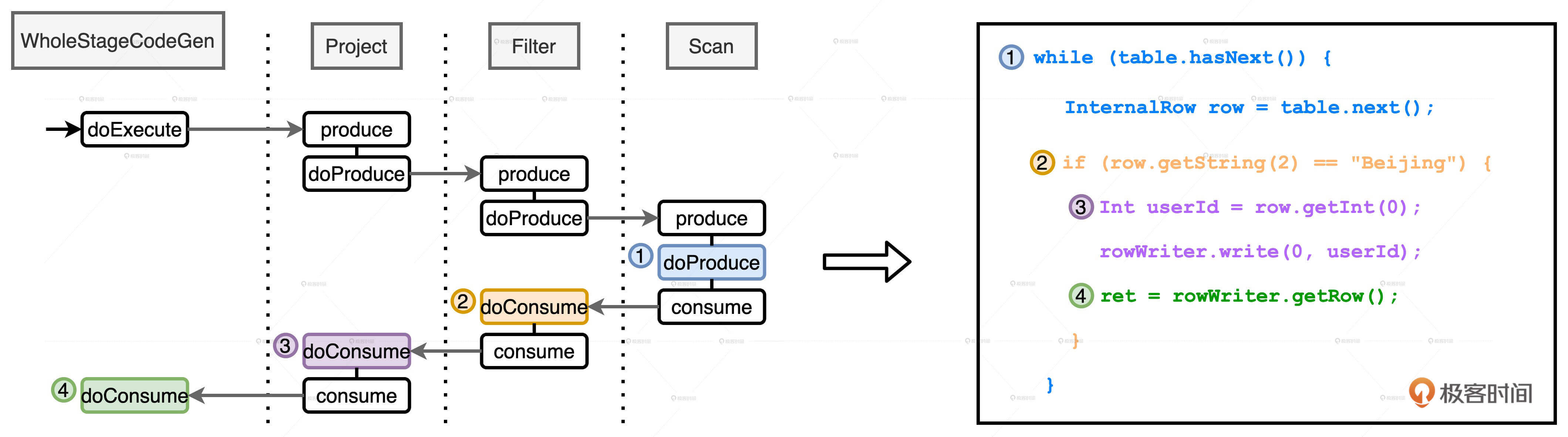
Spark 3.0
AQE
具体概念之前已经提到过了,重点说一下关于倾斜的处理。
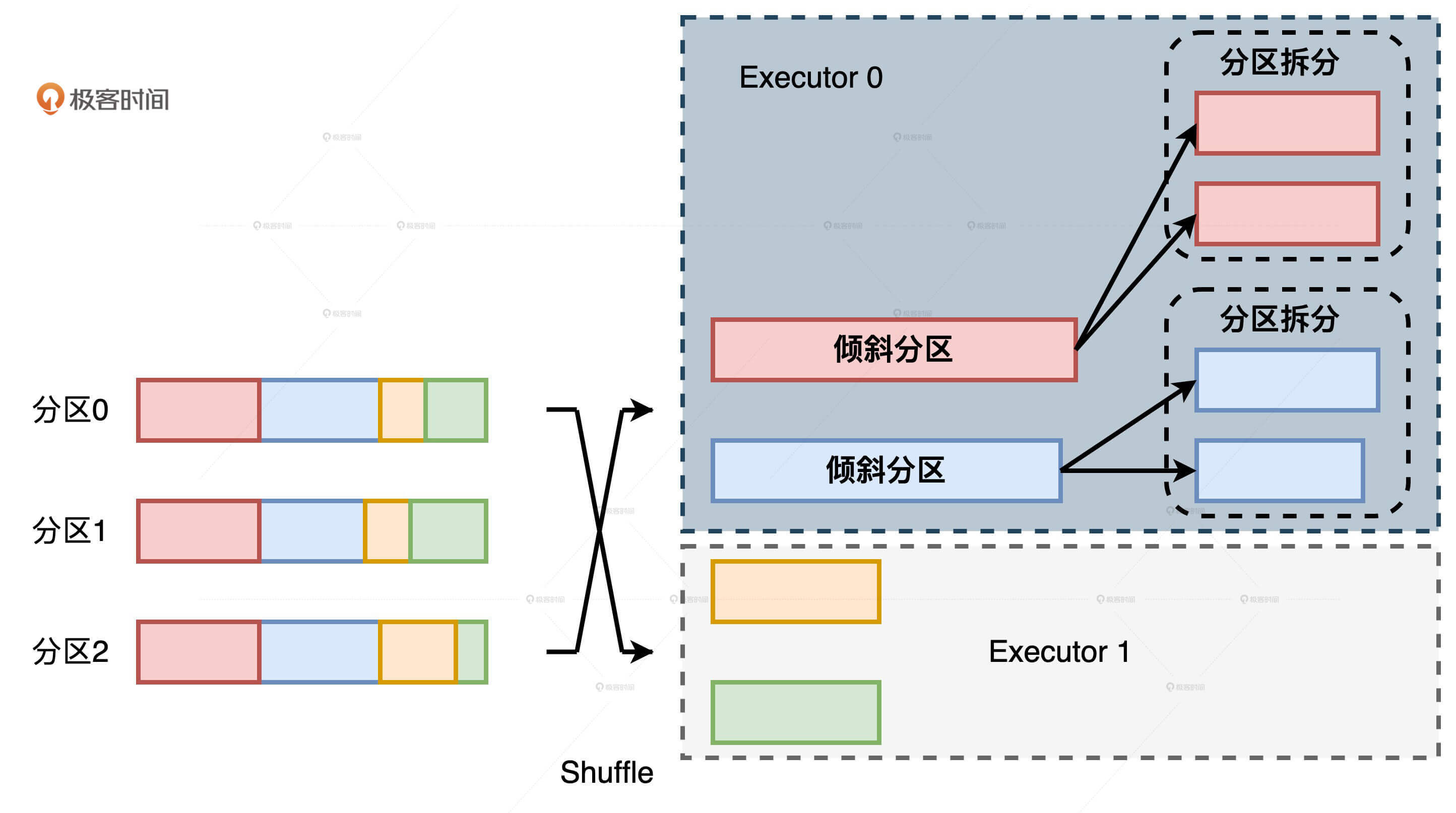
自动倾斜处理的拆分操作也是在 Reduce 阶段执行的。在同一个 Executor 内部,本该由一个 Task 去处理的大分区,被 AQE 拆成多个小分区并交由多个 Task 去计算。这样一来,Task 之间的计算负载就可以得到平衡。但是,这并不能解决不同 Executors 之间的负载均衡问题。
我们来举个例子,假设有个 Shuffle 操作,它的 Map 阶段有 3 个分区,Reduce 阶段有 4 个分区。4 个分区中的两个都是倾斜的大分区,而且这两个倾斜的大分区刚好都分发到了 Executor 0。通过下图,我们能够直观地看到,尽管两个大分区被拆分,但横向来看,整个作业的主要负载还是落在了 Executor 0 的身上。Executor 0 的计算能力依然是整个作业的瓶颈,这一点并没有因为分区拆分而得到实质性的缓解。
另外,在数据关联的场景中,对于参与 Join 的两张表,我们暂且把它们记做数据表 1 和数据表 2,如果表 1 存在数据倾斜,表 2 不倾斜,那在关联的过程中,AQE 除了对表 1 做拆分之外,还需要对表 2 对应的数据分区做复制,来保证关联关系不被破坏。
如果现在问题变得更复杂了,左表拆出 M 个分区,右表拆出 N 各分区,那么每张表最终都需要保持 M x N 份分区数据,才能保证关联逻辑的一致性。当 M 和 N 逐渐变大时,AQE 处理数据倾斜所需的计算开销将会面临失控的风险。
总的来说,当应用场景中的数据倾斜比较简单,比如虽然有倾斜但数据分布相对均匀,或是关联计算中只有一边倾斜,我们完全可以依赖 AQE 的自动倾斜处理机制。但是,当我们的场景中数据倾斜变得复杂,比如数据中不同 Key 的分布悬殊,或是参与关联的两表都存在大量的倾斜,我们就需要衡量 AQE 的自动化机制与手工处理倾斜之间的利害得失。
DPP
分区剪裁
如果过滤谓词中包含分区键,那么 Spark SQL 对分区表做扫描的时候,是完全可以跳过(剪掉)不满足谓词条件的分区目录,这就是分区剪裁。
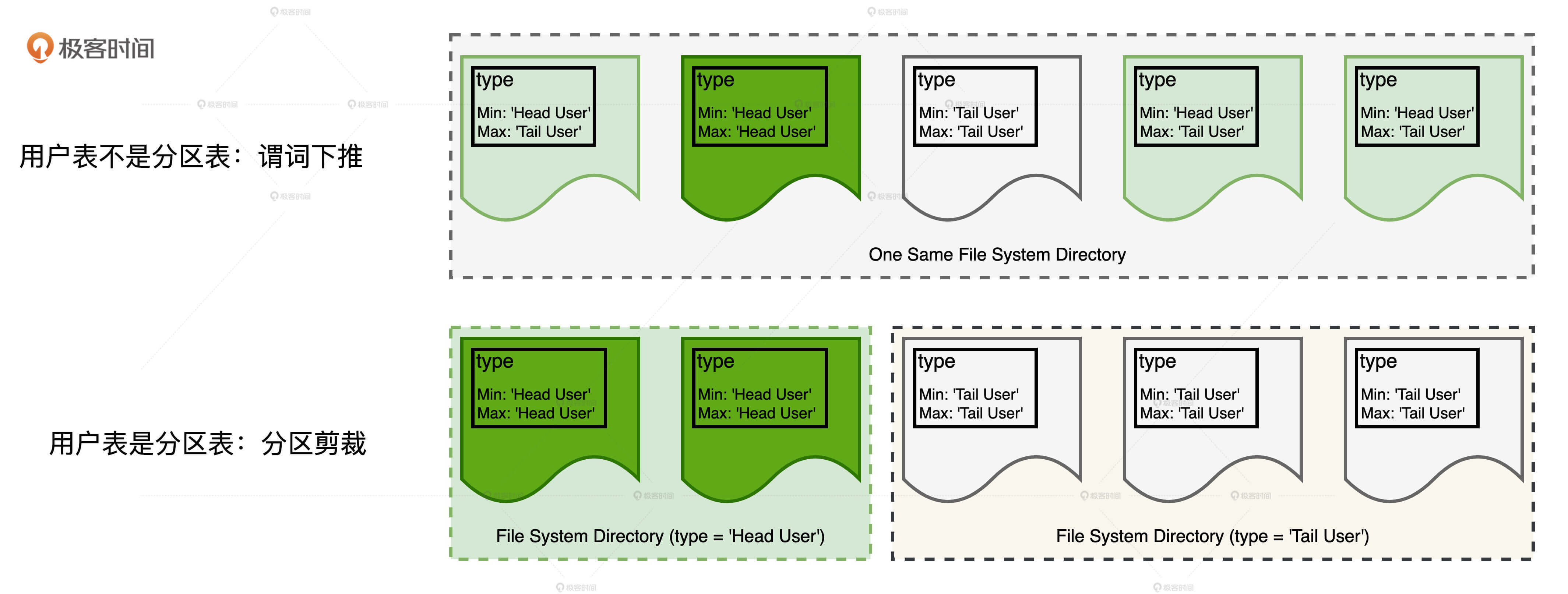
动态分区剪裁
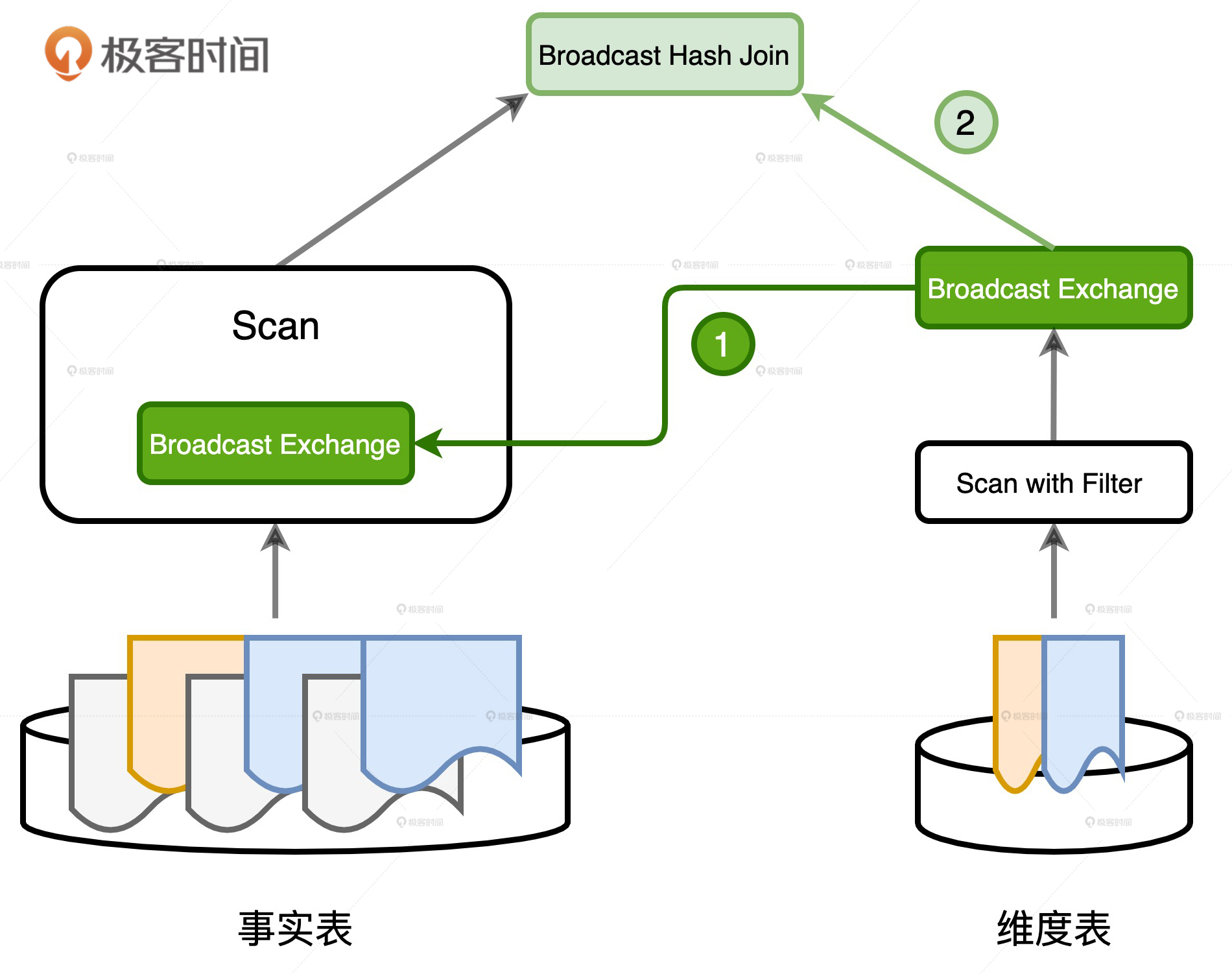
首先,过滤条件 users.type = ‘Head User’会帮助维度表过滤一部分数据。与此同时,维度表的 ID 字段也顺带着经过一轮筛选,如图中的步骤 1 所示。经过这一轮筛选之后,保留下来的 ID 值,仅仅是维度表 ID 全集的一个子集。
然后,在关联关系也就是 orders.userId = users.id 的作用下,过滤效果会通过 users 的 ID 字段传导到事实表的 userId 字段,也就是图中的步骤 2。这样一来,满足关联关系的 userId 值,也是事实表 userId 全集中的一个子集。把满足条件的 userId 作为过滤条件,应用(Apply)到事实表的数据源,就可以做到减少数据扫描量,提升 I/O 效率,如图中的步骤 3 所示。
在数据关联的场景中,开发者要想利用好动态分区剪裁特性,需要注意 3 点:
- 事实表必须是分区表,并且分区字段必须包含 Join Key
- 动态分区剪裁只支持等值 Joins,不支持大于、小于这种不等值关联关系
- 维度表过滤之后的数据集,必须要小于广播阈值,因此,开发者要注意调整配置项 spark.sql.autoBroadcastJoinThreshold
join策略
到目前为止,数据关联总共有 3 种 Join 实现方式。按照出现的时间顺序,分别是嵌套循环连接(NLJ,Nested Loop Join )、排序归并连接(SMJ,Shuffle Sort Merge Join)和哈希连接(HJ,Hash Join)。
NLJ 的工作原理
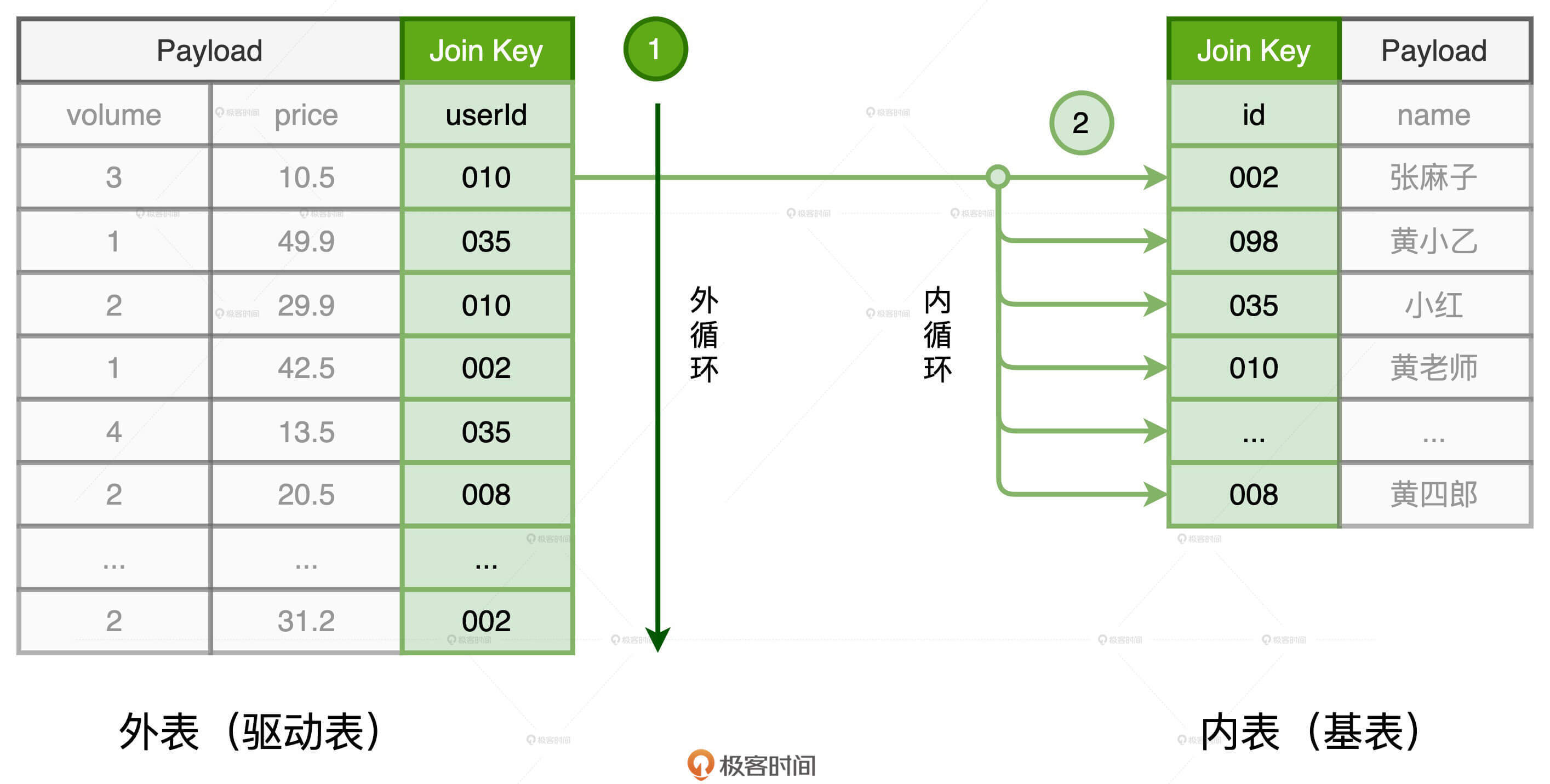
NLJ 是采用“嵌套循环”的方式来实现关联的。也就是说,NLJ 会使用内、外两个嵌套的 for 循环依次扫描外表和内表中的数据记录,判断关联条件是否满足,比如例子中的 orders.userId = users.id,如果满足就把两边的记录拼接在一起,然后对外输出。NLJ 算法的计算复杂度是 O(M * N)。
SMJ 的工作原理
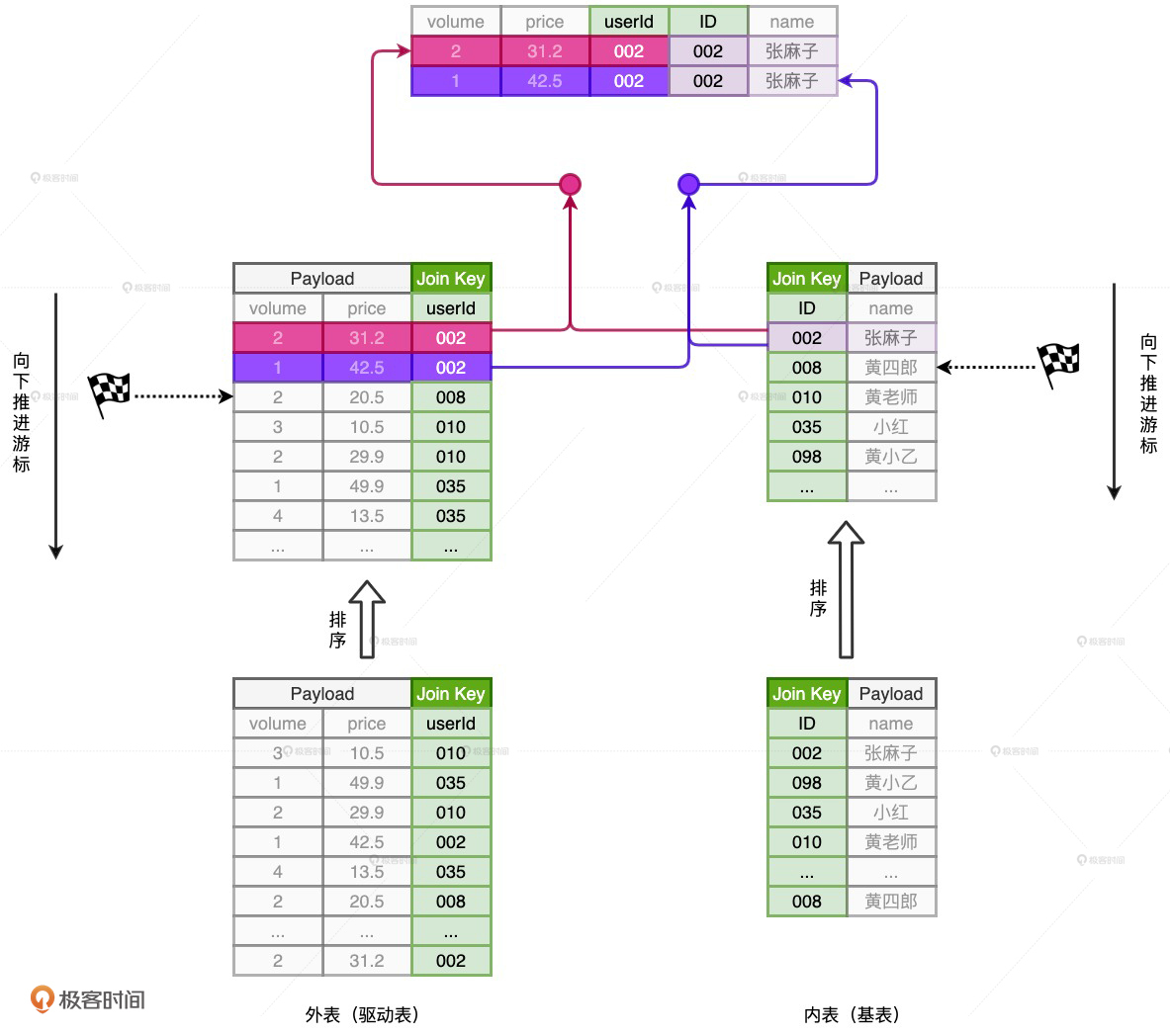
SMJ 算法的计算复杂度为 O(M + N)。不过,SMJ 计算复杂度的降低,仰仗的是两张表已经事先排好序。要知道,排序本身就是一项非常耗时的操作,更何况,为了完成归并关联,参与 Join 的两张表都需要排序。
HJ 的工作原理
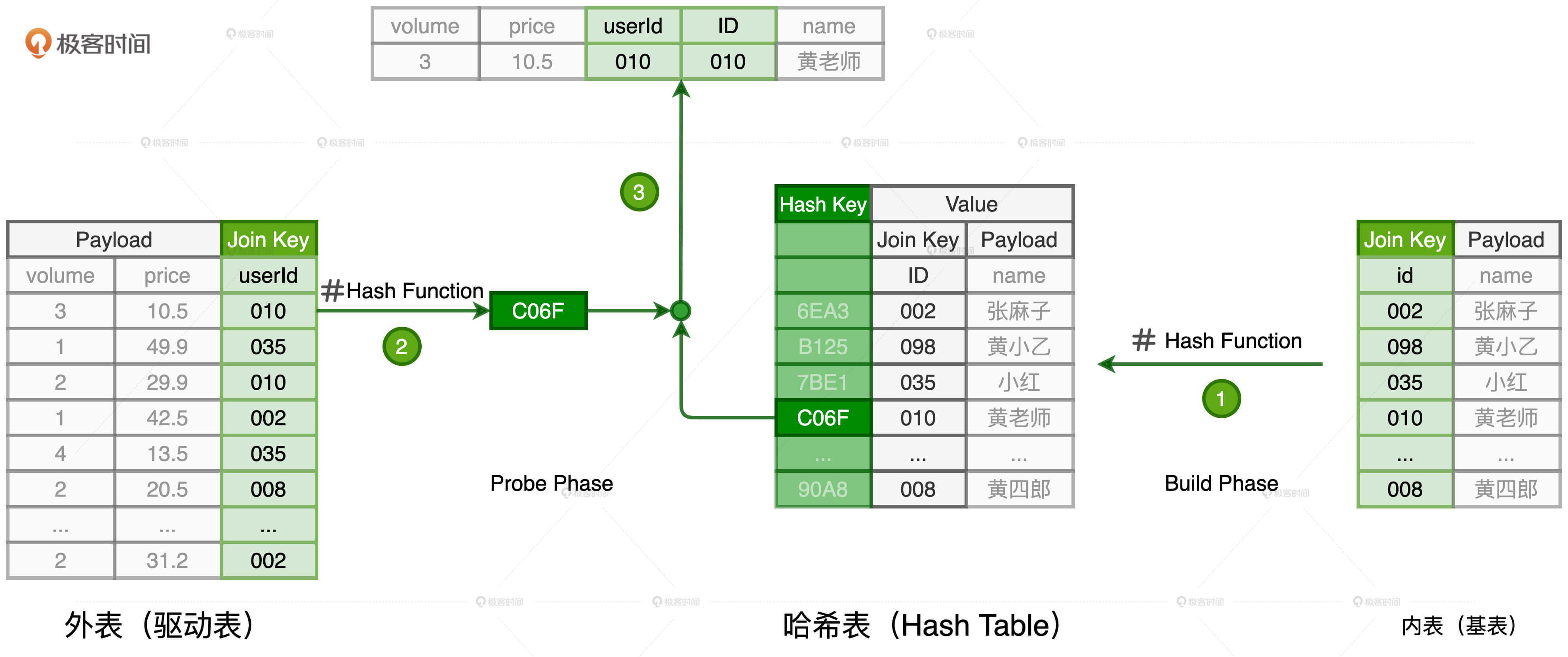
HJ 的计算分为两个阶段,分别是 Build 阶段和 Probe 阶段。在 Build 阶段,基于内表,算法使用既定的哈希函数构建哈希表,如上图的步骤 1 所示。哈希表中的 Key 是 Join Key 应用(Apply)哈希函数之后的哈希值,表中的 Value 同时包含了原始的 Join Key 和 Payload。
在 Probe 阶段,算法遍历每一条数据记录,先是使用同样的哈希函数,以动态的方式(On The Fly)计算 Join Key 的哈希值。然后,用计算得到的哈希值去查询刚刚在 Build 阶段创建好的哈希表。如果查询失败,说明该条记录与维度表中的数据不存在关联关系;如果查询成功,则继续对比两边的 Join Key。如果 Join Key 一致,就把两边的记录进行拼接并输出,从而完成数据关联。
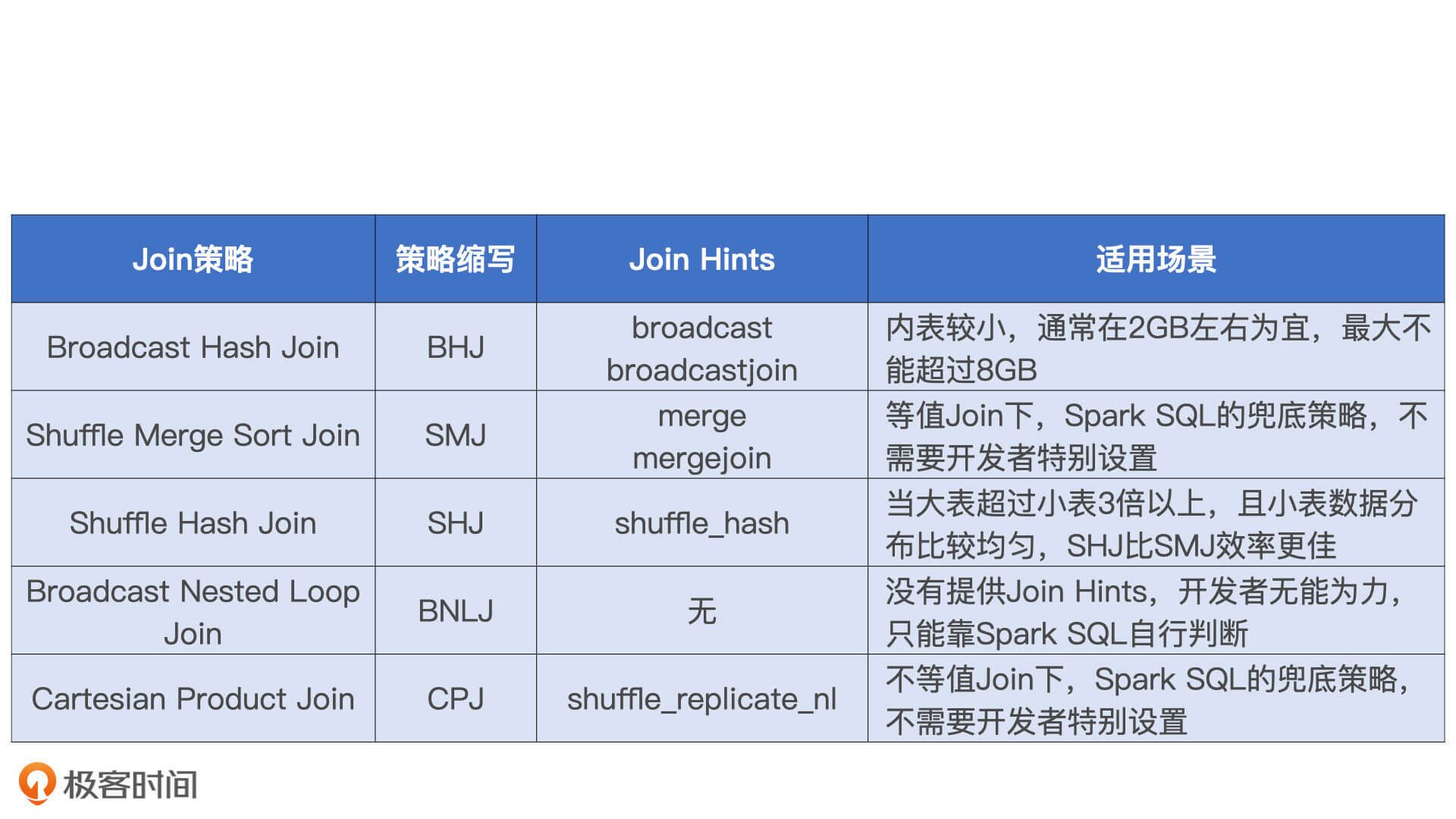
分布式环境下的 Join
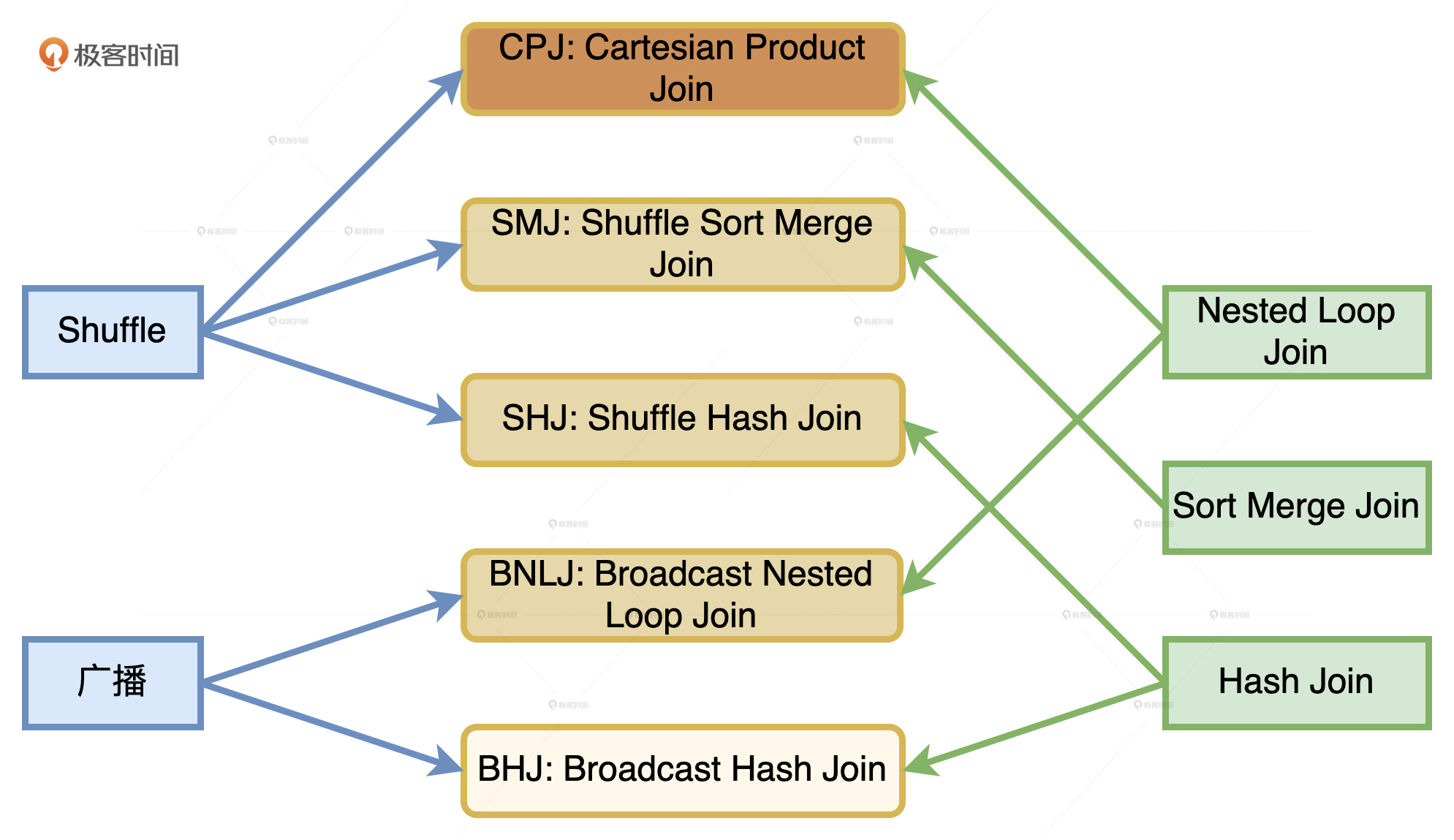
从执行性能来说,6 种策略从上到下由弱变强。
大表Join小表:广播变量容不下小表怎么办?
通常来说,大表与小表尺寸相差 3 倍以上,我们就将其归类为“大表 Join 小表”的计算场景。因此,大表 Join 小表,仅仅意味着参与关联的两张表尺寸悬殊。
BHJ 处理大表 Join 小表时的前提条件是,广播变量能够容纳小表的全量数据。但是,如果小表的数据量超过广播阈值,我们又该怎么办呢?
案例 1:Join Key 远大于 Payload
在第一个案例中,大表 100GB、小表 10GB,它们全都远超广播变量阈值(默认 10MB)。因为小表的尺寸已经超过 8GB,在大于 8GB 的数据集上创建广播变量,Spark 会直接抛出异常,中断任务执行,所以 Spark 是没有办法应用 BHJ 机制的。那我们该怎么办呢?
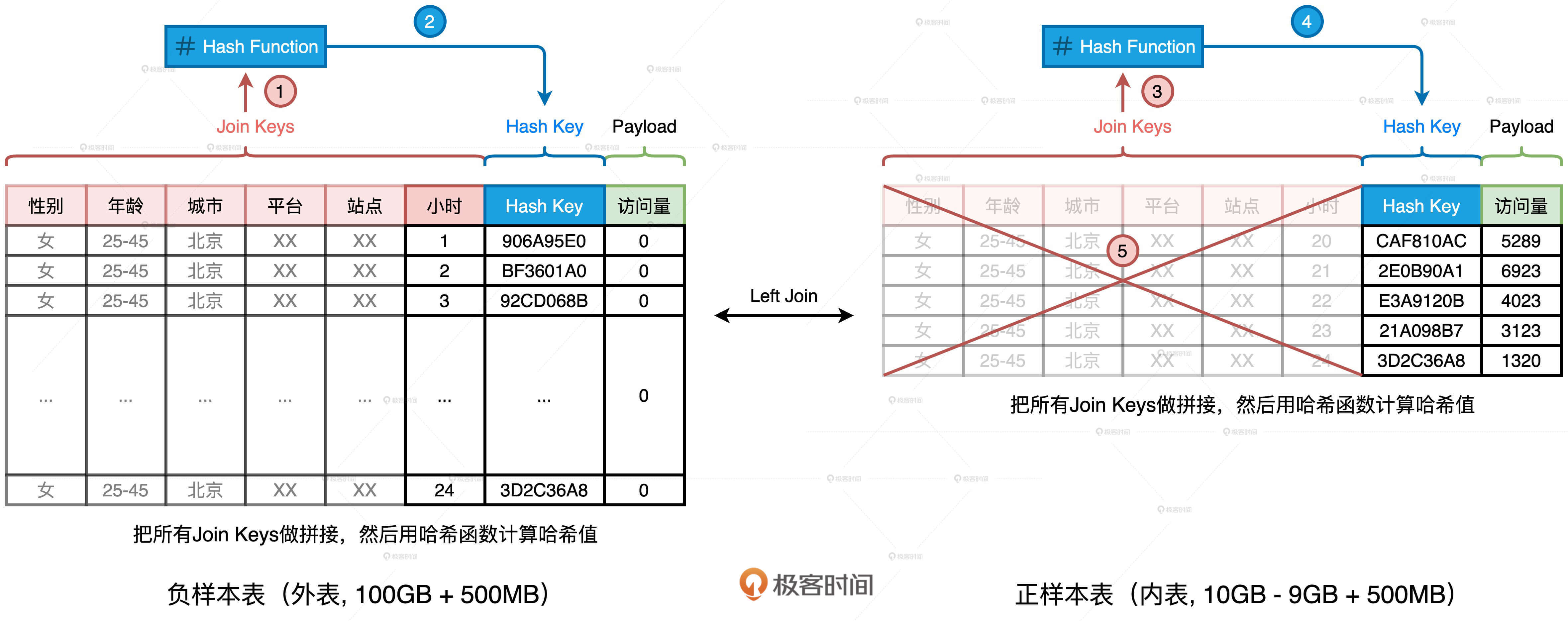
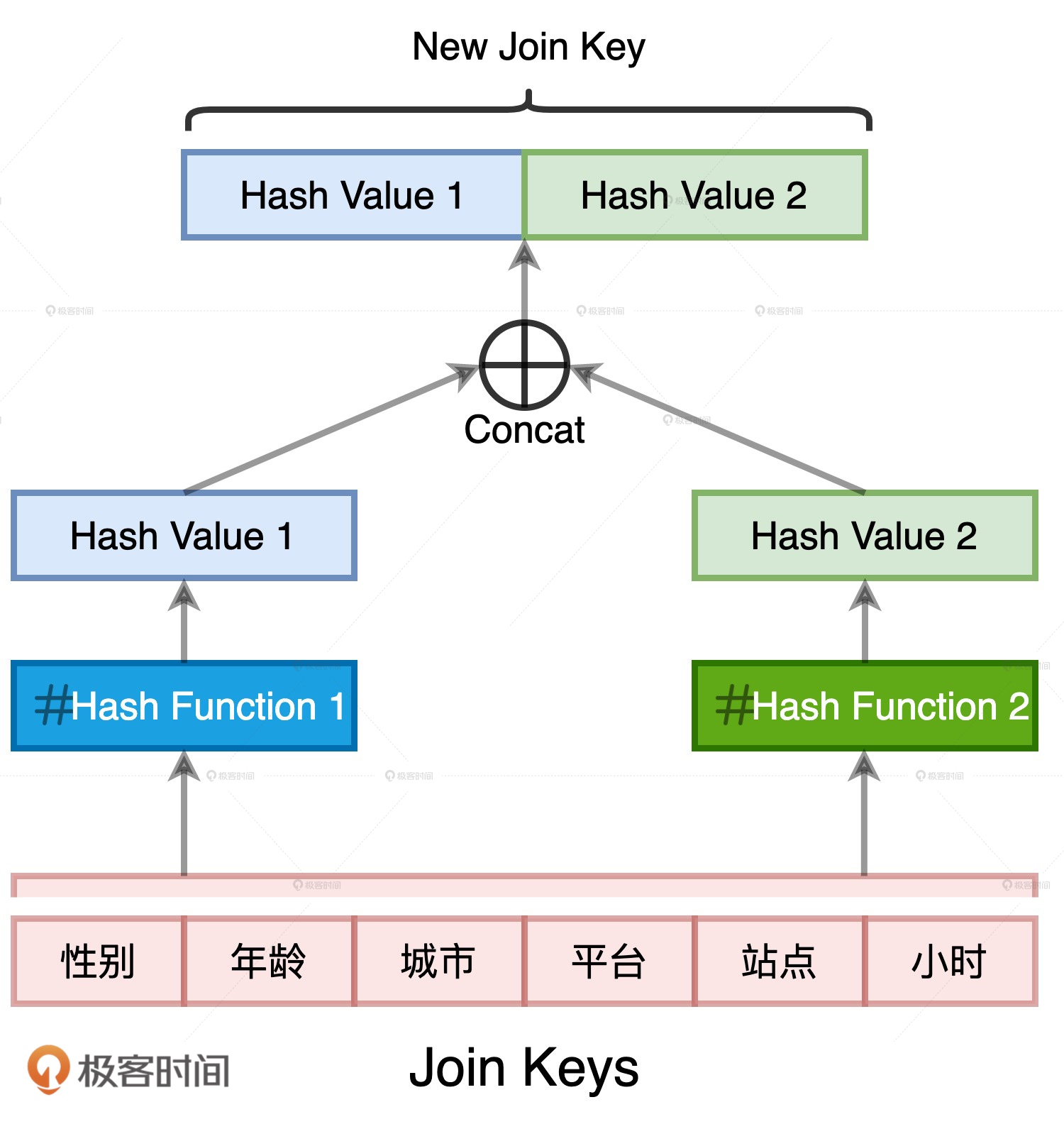
我们完全可以基于现有的 Join Keys 去生成一个全新的数据列,它可以叫“Hash Key”。生成的方法分两步:
- 把所有 Join Keys 拼接在一起,把性别、年龄、一直到小时拼接成一个字符串,如图中步骤 1、3 所示
- 使用哈希算法(如 MD5 或 SHA256)对拼接后的字符串做哈希运算,得到哈希值即为“Hash Key”,如上图步骤 2、4 所示
案例 2:过滤条件的 Selectivity 较高
这个时候我们就要用到 AQE 了,我们知道 AQE 允许 Spark SQL 在运行时动态地调整 Join 策略。我们刚好可以利用这个特性,把最初制定的 SMJ 策略转化为 BHJ 策略(千万别忘了,AQE 默认是关闭的,要想利用它提供的特性,我们得先把 spark.sql.adaptive.enabled 配置项打开)。
不过,即便过滤条件的选择性很高,在千分之一左右,过滤之后的维表还是有 20MB 大小,这个尺寸还是超过了默认值广播阈值 10MB。因此,我们还需要把广播阈值 spark.sql.autoBroadcastJoinThreshold 调高一些。
要想利用 DPP 机制,我们必须要让 orders 成为分区表,也就是做两件事情:
- 创建一张新的订单表 orders_new,并指定 userId 为分区键
- 把原订单表 orders 的全部数据,灌进这张新的订单表 orders_new
案例 3:小表数据分布均匀
当参与 Join 的两张表尺寸相差悬殊且小表数据分布均匀的时候,SHJ 往往比 SMJ 的执行效率更高。
这种情况下,我们不妨使用 Join Hints 来强制 Spark SQL 去选择 SHJ 策略进行关联计算。
大表Join大表(一):“分而治之”
“分而治之”的调优思路是把“大表 Join 大表”降级为“大表 Join 小表”,然后使用上一讲中“大表 Join 小表”的调优方法来解决性能问题。它的核心思想是,先把一个复杂任务拆解成多个简单任务,再合并多个简单任务的计算结果。
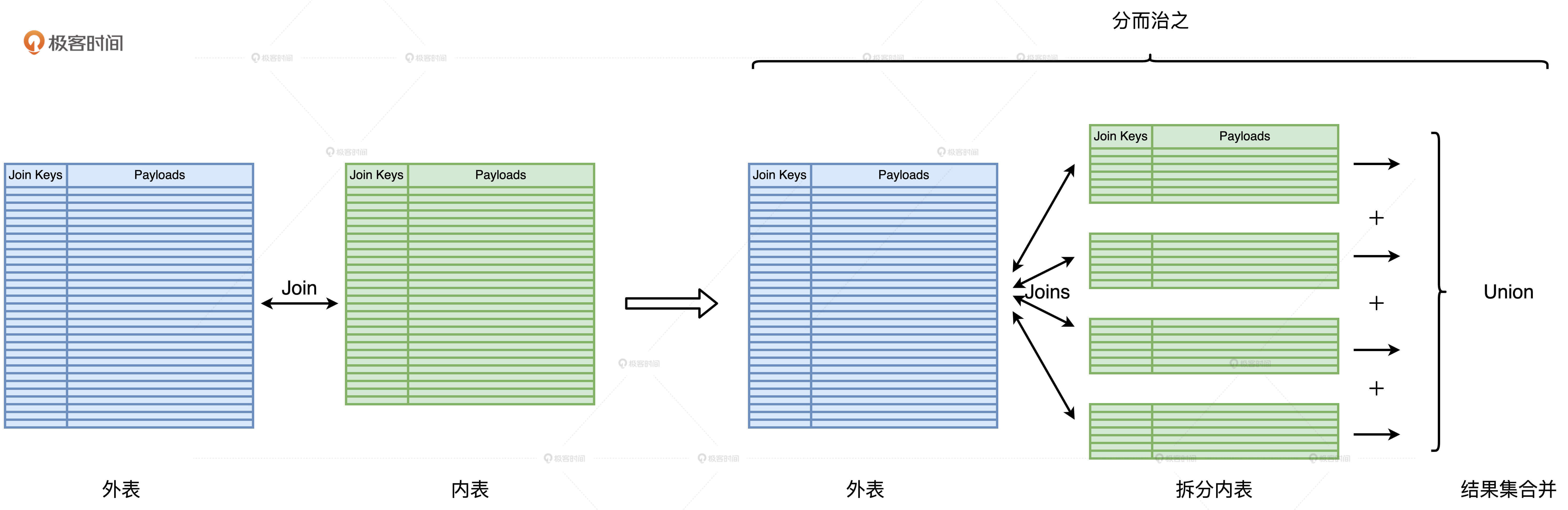
如何避免外表的重复扫描?
内表拆分之后,外表就要分别和所有的子表做关联,尽管每一个关联都变成了“大表 Join 小表”并转化为 BHJ,但是在 Spark 的运行机制下,每一次关联计算都需要重新、重头扫描外表的全量数据。毫无疑问,这样的操作是让人无法接受的。这就是“分而治之”中另一个关键的环节:外表的重复扫描。
有了DPP的帮助,我们方便了许多。
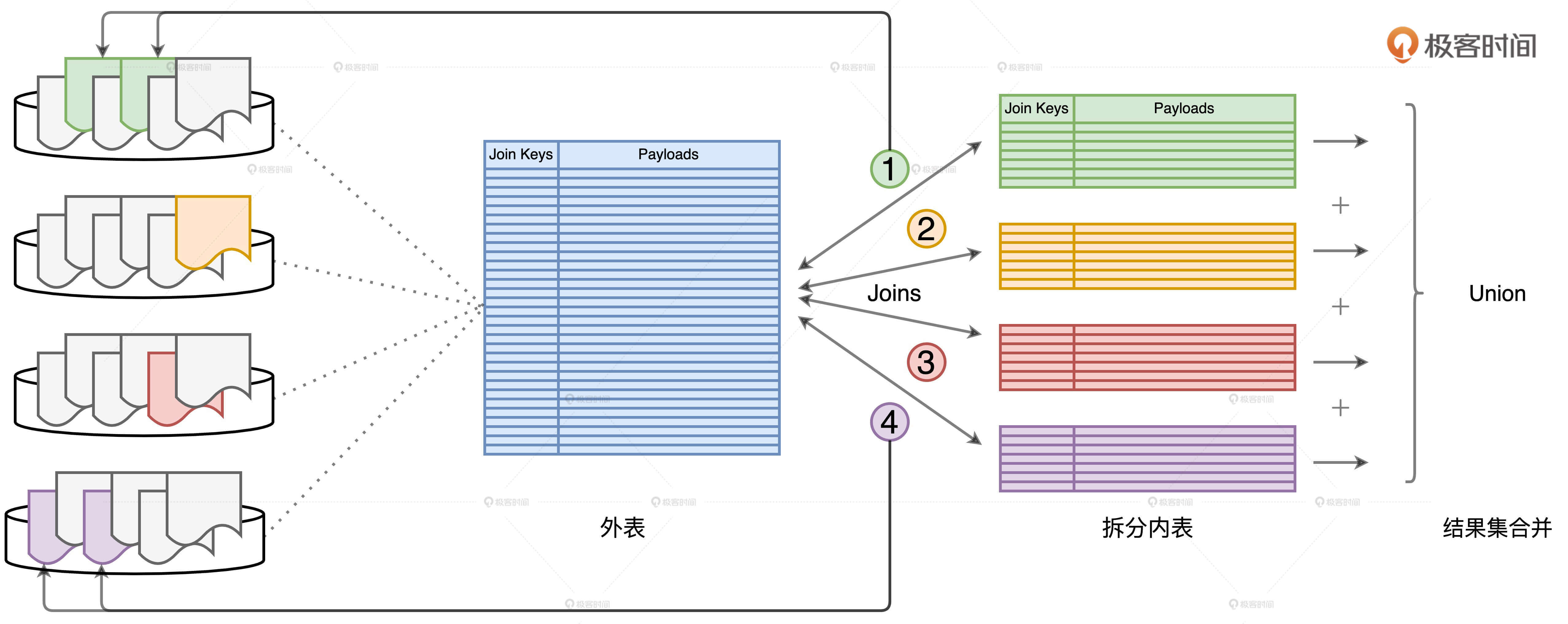
不难发现,每个子查询只扫描外表的一部分、一个子集,所有这些子集加起来,刚好就是外表的全量数据。因此,利用“分而治之”的调优技巧,端到端的关联计算仅需对外表做一次完整的全量扫描即可。
大表Join大表(二):负隅顽抗
负隅顽抗指的是,当内表没法做到均匀拆分,或是外表压根就没有分区键,不能利用 DPP,只能依赖 Shuffle Join,去完成大表与大表的情况下,我们可以采用的调优方法和手段。
数据分布均匀
这两个条件与数据表本身的尺寸无关,只与其是否分布均匀有关。不过,为了确保 Shuffle Hash Join 计算的稳定性,我们需要特别注意上面列出的第二个条件,也就是内表所有的数据分片都能够放入内存。
其实,只要处理好并行度、并发度与执行内存之间的关系,我们就可以让内表的每一个数据分片都恰好放入执行内存中。
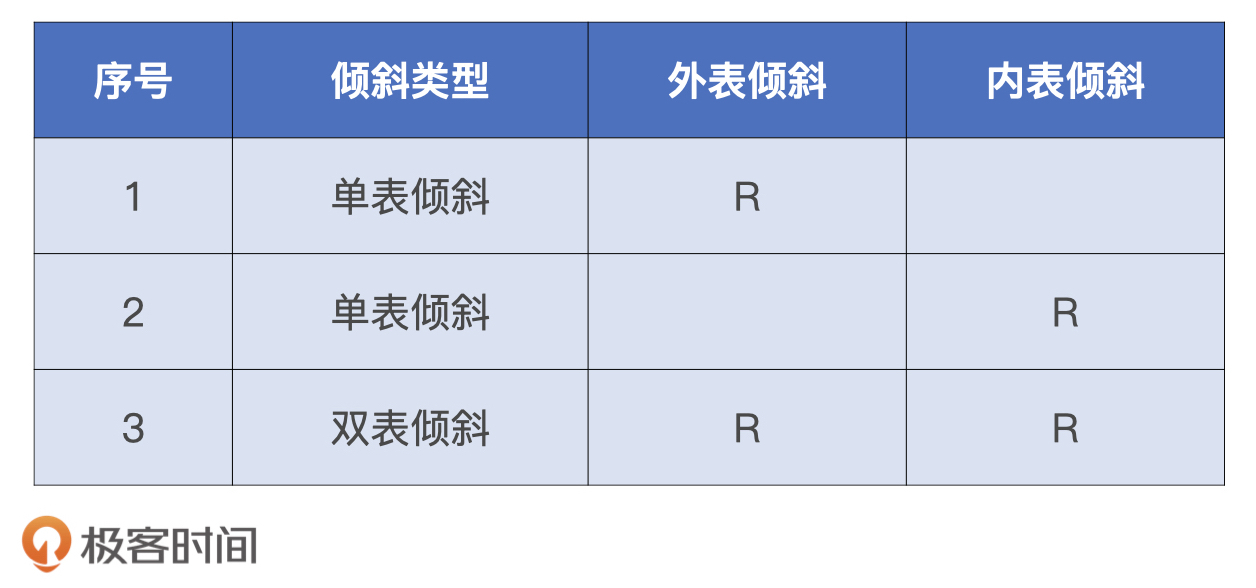
数据倾斜
学过 AQE 之后,要应对数据倾斜,想必你很快就会想到 AQE 的特性:自动倾斜处理。给定如下配置项参数,Spark SQL 在运行时可以将策略 OptimizeSkewedJoin 插入到物理计划中,自动完成 Join 过程中对于数据倾斜的处理。
有了 AQE 的自动倾斜处理特性,在应对数据倾斜问题的时候,我们确实能够大幅节省开发成本。不过,天下没有免费的午餐,AQE 的倾斜处理是以 Task 为粒度的,这意味着原本 Executors 之间的负载倾斜并没有得到根本改善。如下图。
解决方法如下。
对于外表中所有的 Join Keys,我们先按照是否存在倾斜把它们分为两组。一组是存在倾斜问题的 Join Keys,另一组是分布均匀的 Join Keys。因为给定两组不同的 Join Keys,相应地我们把内表的数据也分为两份。
对于 Join Keys 分布均匀的数据部分,我们可以沿用把 Shuffle Sort Merge Join 转化为 Shuffle Hash Join 的方法。
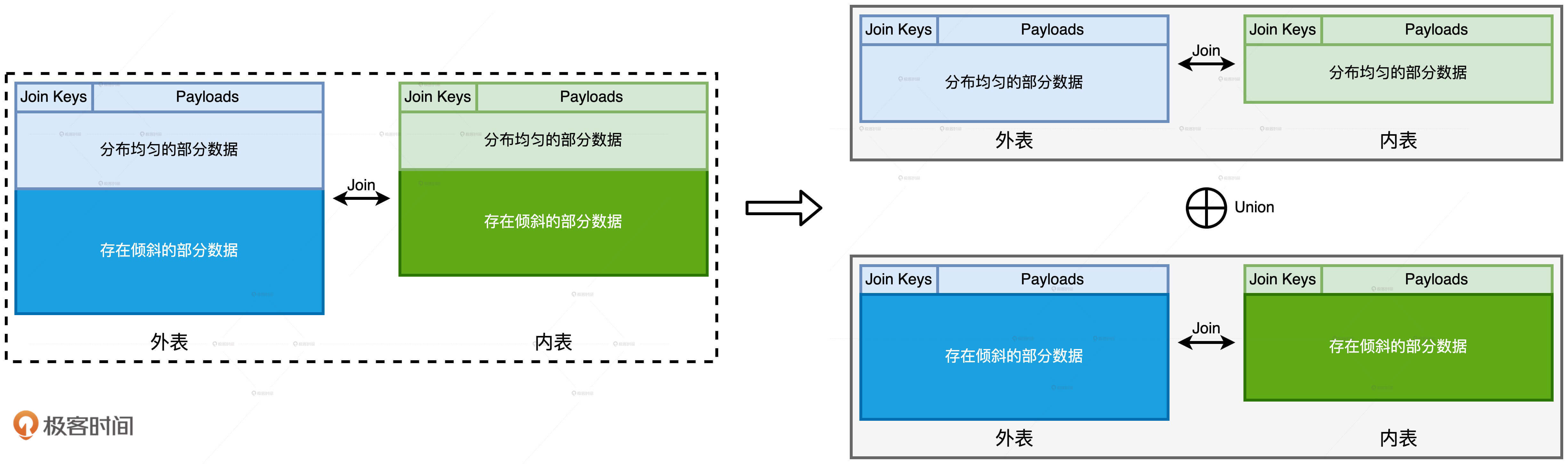
对于 Join Keys 存在倾斜问题的数据部分,我们就需要借助“两阶段 Shuffle”的调优技巧,来平衡 Executors 之间的工作负载。
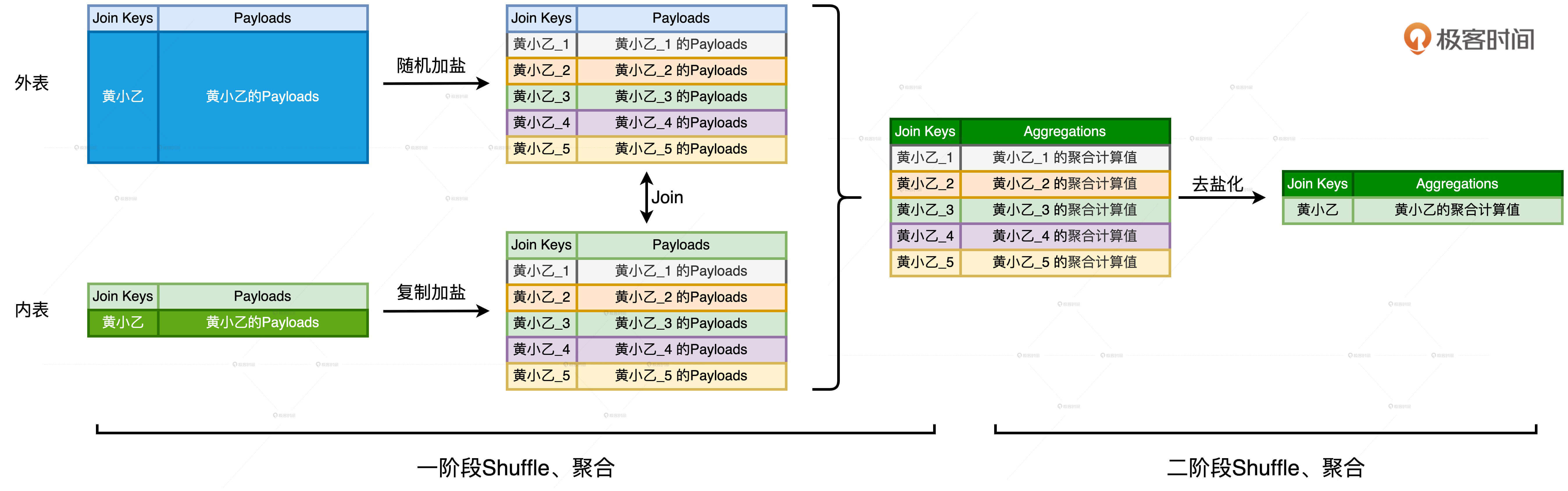
外表的处理称作“随机加盐”,具体的操作方法是,对于任意一个倾斜的 Join Key,我们都给它加上 1 到 #N 之间的一个随机后缀。粒度使用executors的数量是一个不错的选择。
内表的处理称为“复制加盐”,具体的操作方法是,对于任意一个倾斜的 Join Key,我们都把原数据复制(#N – 1)份,从而得到 #N 份数据副本。
但这个手法有一个缺陷,如果Shuffle中涉及的聚合计算需要以排序为前提,那么加盐之后的优化手段,也就是“两阶段Shuffle”,可能会破坏原先的计算逻辑。
总结
本文链接: http://woaixiaoyuyu.github.io/2021/09/05/%E8%B0%83%E4%BC%98/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!