
又是实习中学习的一天,同时今天提到了谓词下推这个概念,我表示没听过,而且他们说这是很基础的概念,赶紧弥补一下。
谓词下推 Predicate PushDown
谓词下推的目的:将过滤条件尽可能地下沉到数据源端
谓词,用来描述或判定客体性质、特征或者客体之间关系的词项,英文翻译为predicate,而谓词下推的英文Predicate Pushdown中的谓词指返回bool值即true和false的函数,或是隐式转换为bool的函数。如SQL中的谓词主要有 like、between、is null、in、=、!=等,再比如Spark SQL中的filter算子等。
谓词下推的含义为将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据,一般的数据库或查询系统都支持谓词下推。
列裁剪 Column Pruning 和 映射下推 Project PushDown
列裁剪和映射下推的目的:过滤掉查询不需要使用到的列
列裁剪ColumnPruning 指把那些查询不需要的字段过滤掉,使得扫描的数据量减少。如果底层的文件格式为列式存储(比如 Parquet),则可以进一步映射下推,映射可以理解为表结构映射,Parquet每一列的所有值都是连续存储的,所以分区取出每一列的所有值就可以实现TableScan算子,而避免扫描整个表文件内容
Spark SQL处理SQL流程
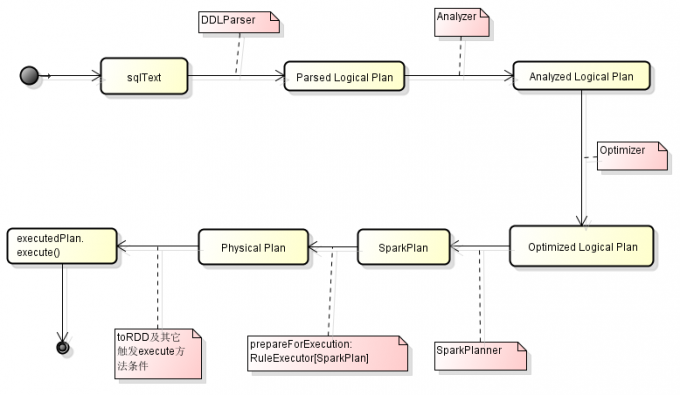
词法解析:对SQL语句进行初步结构化,类似于分词语法分析,语义分析:对结构化的SQL进行规则分析,比如判断数据库是否存在,语法是否符合SQL语法规则等逻辑计划:对合规后的SQL生成逻辑执行计划,其中就行语法优化和逻辑改写物理计划:对逻辑计划生成Spark DAG图Execute:执行物理计划
Spark SQL逻辑计划优化
orderBy/filter
读取一张parquet存储的hive表,对某列进行排序orderBy,排序结果根据filter,最终选择一列为想要的DataFrame
将Analyzed Logical Plan原始逻辑的处理流程图和Physical Plan最终的物理计划流程图进行对比:
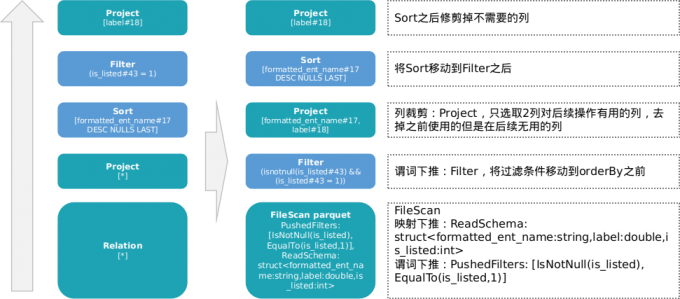
由此可见在读取parquet阶段就将过滤条件下推到数据源,并且将需要的列也下推到数据源而不是原计划中的select *。
groupBy/count
另取一个dataframe,对一列做groupBy聚合操作,然后求count
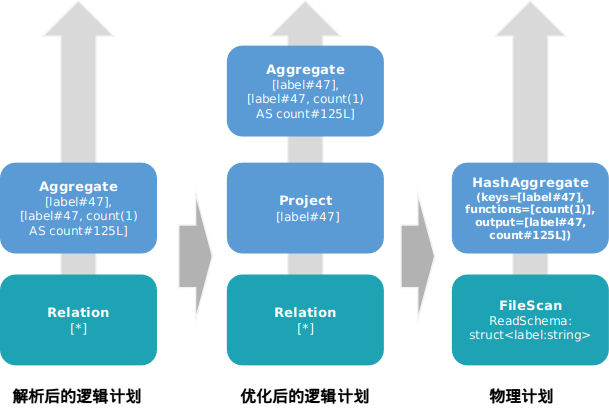
对一列进行groupBy聚合计数只需要所有数据的一个字段,因此在逻辑计划优化中加入Project映射裁剪,并且在物理计划中再次下推到数据源
Join/filter
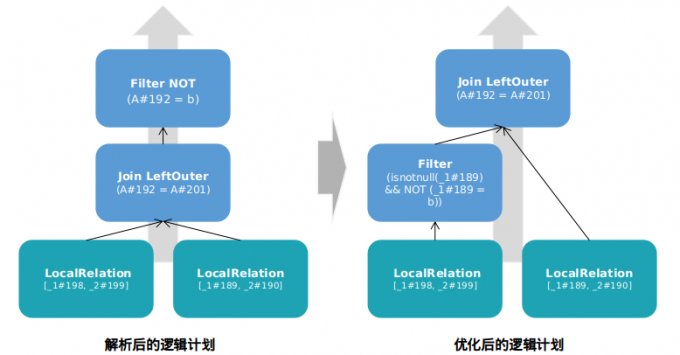
在join操作后面加入filter,创建两个dataframe备用,join后新dataframe使用filter过滤
本文链接: http://woaixiaoyuyu.github.io/2021/08/25/Spark%20SQL%E8%B0%93%E8%AF%8D%E4%B8%8B%E6%8E%A8%E8%B0%93%E8%AF%8D%E4%B8%8B%E6%8E%A8:%E5%88%97%E8%A3%81%E5%89%AA:%E6%98%A0%E5%B0%84%E4%B8%8B%E6%8E%A8/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!