
关于元数据管理和数据血缘框架atlas的学习
参考链接
https://blog.csdn.net/Zsigner/article/details/115306506
https://atlas.apache.org/#/HighAvailability
https://blog.csdn.net/Milkcoffeezhu/article/details/107049699
数据仓库元数据管理
元数据(MetaData)狭义的解释是用来描述数据的数据。广义的来看,除了业务逻辑直接读写处理的那些业务数据,所有其它用来维持整个系统运转所需的信息/数据都可以叫作元数据。如数据库中表的Schema信息,任务的血缘关系,用户和脚本/任务的权限映射关系信息等。
管理元数据的目的,是为了让用户能够更高效的使用数据,也是为了让平台管理人员能更加有效的做好数据的维护管理工作。
但通常这些元数据信息是散落在平台的各个系统,各种流程之中的,它们的管理也可能或多或少可以通过各种子系统自身的工具,方案或流程逻辑来实现。
元数据管理平台很重要的一个功能就是信息的收集,至于收集哪些信息,取决于业务的需求和需要解决的目标问题。
元数据管理平台还需要考虑如何以恰当的形式对这些元数据信息进行展示;进一步的,如何将这些元数据信息通过服务的形式提供给周边上下游系统使用,真正帮助大数据平台完成质量管理的闭环工作。
应该收集那些信息,没有绝对的标准,但是对大数据开发平台来说,常见的元数据信息包括:
- 表结构信息
- 数据的空间存储,读写记录,权限归属和其它各类统计信息
- 数据的血缘关系信息
- 数据的业务属性信息
数据血缘关系
血缘信息或者叫做Lineage的血统信息是什么,简单的说就是数据之间的上下游来源去向关系,数据从哪里来到哪里去。如果一个数据有问题,可以根据血缘关系往上游排查,看看到底在哪个环节出了问题。此外也可以通过数据的血缘关系,建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等。
分析数据的血缘关系看起来简单,但真的要做起来,并不容易,因为数据的来源多种多样,加工数据的手段,所使用的计算框架可能也各不相同,此外也不是所有的系统天生都具备获取相关信息的能力。而针对不同的系统,血缘关系具体能够分析到的粒度可能也不一样,有些能做到表级别,有些甚至可以做到字段级别。
以Hive表为例,通过分析Hive脚本的执行计划,是可以做到相对精确的定位出字段级别的数据血缘关系的。而如果是一个MapReduce任务生成的数据,从外部来看,可能就只能通过分析MR任务输出的Log日志信息来粗略判断目录级别的读写关系,从而间接推导数据的血缘依赖关系了。
数据的业务属性信息
业务属性信息都有哪些呢?如一张数据表的统计口径信息,这张表干什么用的,各个字段的具体统计方式,业务描述,业务标签,脚本逻辑的历史变迁记录,变迁原因等,此外还包括对应的数据表格是由谁负责开发的,具体数据的业务部门归属等。数据的业务属性信息,首先是为业务服务的,它的采集和展示也就需要尽可能的和业务环境相融合,只有这样才能真正发挥这部分元数据信息的作用。
What is Atlas
很长一段时间内,市面都没有成熟的大数据元数据管理解决方案。直到2015年,Hortonworks终于坐不住了,约了一众小伙伴公司倡议:咱们开始整个数据治理方案吧。然后,包含数据分类、集中策略引擎、数据血缘、安全和生命周期管理功能的Atlas应运而生。(类似的产品还有Linkedin 在2016年新开源的项目 WhereHows ) 。
Atlas是Hadoop平台元数据框架;
Atlas是一组可扩展的核心基础治理服务,使企业能够有效,高效地满足Hadoop中的合规性要求,并能与整个企业数据生态系统集成;
Apache Atlas为组织提供了开放的元数据管理和治理功能,以建立数据资产的目录,对这些资产进行分类和治理,并为IT团队、数据分析团队提供围绕这些数据资产的协作功能。
Atlas High Level Architecture - Overview
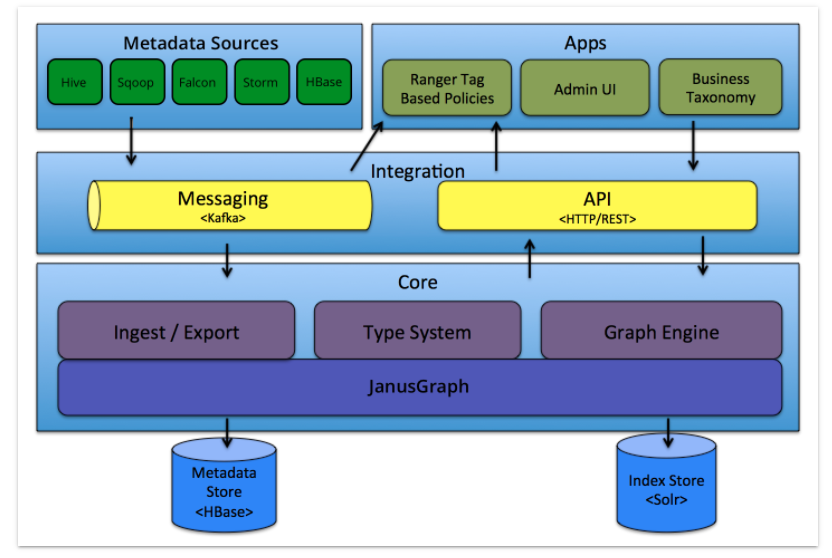
Atlas由元数据的收集,存储和查询展示三部分核心组件组成。此外,还会有一个管理后台对整体元数据的采集流程以及元数据格式定义和服务的部署等各项内容进行配置管理。
Atlas包括以下组件:
Core。Atlas功能核心组件,提供元数据的获取与导出(Ingets/Export)、类型系统(TypeSystem)、元数据存储索引查询等核心功能
图形引擎: Atlas在内部使用Graph模型持久保存它管理的元数据对象。这种方法提供了很大的灵活性,可以有效地处理元数据对象之间的丰富关系。图形引擎组件负责在Atlas类型系统的类型和实体之间进行转换,以及底层图形持久性模型。除了管理图形对象之外,图形引擎还为元数据对象创建适当的索引,以便可以有效地搜索它们。 Atlas使用JanusGraph存储元数据对象。
Integration。Atlas对外集成模块。外部组件的元数据通过该模块将元数据交给Atlas管理
Metadata source。Atlas支持的元数据数据源,以插件形式提供。当前支持从以下来源提取和管理元数据:
1
2
3
4
5
6
7
8
9Hive
HBase
Sqoop
Kafka
StormApplications。Atlas的上层应用,可以用来查询由Atlas管理的元数据类型和对象
Graph Engine(图计算引擎)。Altas使用图模型管理元数据对象。图数据库提供了极大的灵活性,并能有效处理元数据对象之间的关系。除了管理图对象之外,图计算引擎还为元数据对象创建适当的索引,以便进行高效的访问。在Atlas 1.0 之前采用Titan作为图存储引擎,从1.0开始采用 JanusGraph 作为图存储引擎。JanusGraph 底层又分为两块:
Metadata Store。采用 HBase 存储 Atlas 管理的元数据;
Index Store。采用Solr存储元数据的索引,便于高效搜索;
Type System
Type
Atlas允许用户为他们想要管理的元数据对象定义模型。该模型由称为
type(类型)的定义组成。称为entities(实体)的type(类型)实例表示受管理的实际元数据对象。 Type System是一个允许用户定义和管理类型和实体的组件。开箱即用的Atlas管理的所有元数据对象(例如Hive表)都使用类型建模并表示为实体。要在Atlas中存储新类型的元数据,需要了解类型系统组件的概念。Type具有元类型。Atlas中有以下元类型:
- 原始元类型(Primitive metatypes):boolean,byte,short,int,long,float,double,biginteger,bigdecimal,string,date
- 枚举元型(Enum metatypes)
- 集合元类型(Collection metatypes:):array, map
- 复合元类型(Composite metatypes):Entity, Struct, Classification, Relationship
举个例子,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// Atlas中的类型(Type)由Name唯一标识
// 实体(Entity)和分类(Classification)类型可以从其他类型继承,称为“超类型/父类型”(supertype) ,它包括在超类型中定义的属性。这允许建模者在一组相关类型等中定义公共属性。类似于面向对象语言如何为类定义父类
// 具有元类型Entity,Struct,Classification或Relationship的类型可以具有属性的集合。每个属性都有一个名称(例如: name)
Name: hive_table
TypeCategory: Entity
SuperTypes: DataSet
Attributes:
name: string
db: hive_db
owner: string
createTime: date
lastAccessTime: date
comment: string
retention: int
sd: hive_storagedesc
partitionKeys: array<hive_column>
aliases: array<string>
columns: array<hive_column>
parameters: map<string,string>
viewOriginalText: string
viewExpandedText: string
tableType: string
temporary: booleanEntities(实体)
Atlas中的
entity是type的特定值或实例,因此表示现实世界中的特定元数据对象。用我们对面向对象编程语言的类比,实例(instance)是某个类(Class)的对象(Object)。实体的其中一个示例就是Hive表。Hive在’default’数据库中有一个名为’customers’的表。该表是hive_table类型的Atlas中的“实体”。由于是实体类型的实例,它将具有作为Hive表’type’的一部分的每个属性的值,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 实体类型的每个实例都由唯一标识符GUID标识。此GUID由Atlas服务器在定义对象时生成,并在实体的整个生命周期内保持不变。在任何时间点,都可以使用其GUID访问此特定实体
// 在此示例中,'customers'表是'hive_table'类型
// 实体类型的实例具有标识(具有GUID值),并且可以从其他实体引用(例如,从hive_table实体引用hive_db实体)
guid: "9ba387dd-fa76-429c-b791-ffc338d3c91f"
typeName: "hive_table"
status: "ACTIVE"
values:
name: “customers”
db: { "guid": "b42c6cfc-c1e7-42fd-a9e6-890e0adf33bc", "typeName": "hive_db" }
owner: “admin”
createTime: 1490761686029
updateTime: 1516298102877
comment: null
retention: 0
sd: { "guid": "ff58025f-6854-4195-9f75-3a3058dd8dcf", "typeName": "hive_storagedesc" }
partitionKeys: null
aliases: null
columns: [ { "guid": ""65e2204f-6a23-4130-934a-9679af6a211f", "typeName": "hive_column" }, { "guid": ""d726de70-faca-46fb-9c99-cf04f6b579a6", "typeName": "hive_column" }, ...]
parameters: { "transient_lastDdlTime": "1466403208"}
viewOriginalText: null
viewExpandedText: null
tableType: “MANAGED_TABLE”
temporary: falseAttributes(属性)
attributes具有以下properties:
1
2
3
4
5
6name: string,
typeName: string,
isOptional: boolean,
isIndexable: boolean,
isUnique: boolean,
cardinality: enum
Glossary
A Glossary provides appropriate vocabularies for business users and it allows the terms (words) to be related to each other and categorized so that they can be understood in different contexts. These terms can be then mapped to assets like a Database, tables, columns etc. This helps abstract the technical jargon associated with the repositories and allows the user to discover/work with data in the vocabulary that is more familiar to them.
Atlas的术语表(Glossary)提供了一些适当的“单词”,这些“单词”能彼此进行关连和分类,以便业务用户在使用的时候,即使在不同的上下文中也能很好的理解它们。此外,这些术语也是可以映射到数据资产中的,比如:数据库,表,列等。
术语表抽象出了和数据相关的专业术语,使得用户能以他们更熟悉的方式去查找和使用数据。
1. 功能
- 能够使用自然语言(技术术语和/或业务术语)定义丰富的术语词汇表。
- 能够将术语在语义上相互关联。
- 能够将资产映射到术语表中。
- 能够按类别划分这些术语。这为术语增加了更多的上下文。
- 允许按层次结构排列类别,能展示更广泛和更精细的范围。
- 从元数据中独立管理术语表。
2. 术语(Term)
对于企业来说术语作用的非常大的。对于有用且有意义的术语,需要围绕其用途和上下文进行分组。 Apache Atlas中的术语必须具有唯一的qualifiedName,可以有相同名称的术语,但它们不能属于同一个术语表。具有相同名称的术语只能存在于不同的术语表中。
术语名称可以包含空格,下划线和短划线(作为引用单词的自然方式)但不包含“。”或“@”,因为qualifiedName的格式为:<术语>@<术语限定名>。限定名称可以更轻松地使用特定术语。
术语只能属于单个术语表,并且它们的生命周期也是相同的,如果删除术语表,则术语也会被删除。术语可以属于零个或多个类别,这允许将它们限定为更小或更大的上下文。
可以在Apache Atlas中为一个或多个实体分配/链接一个术语。可以使用分类(classifications,类似标签的作用)对术语进行分类,并将相同的分类应用于分配术语的实体。
3. 类别(Category)
类别是组织术语的一种方式,以便可以丰富术语的上下文。
类别可能包含也可能不包含层次结构,即子类别层次结构。类别的qualifiedName是使用它在术语表中的分层位置导出的,例如:<类别名称>.<父类别限定名>。当发生任何层级更改时,此限定名称都会更新,例如:添加父类别,删除父类别或更改父类别。
4. Atlas Web UI
Apache Atlas UI提供了友好的用户界面,可以使用术语表相关的功能,其中包括:
- 创建术语表,术语和类别
- 在术语之间创建各种关系: synonymns(同义词),antonymns(反义词),seeAlso(参考)
- 调整类别的层次结构中
- 为实体分配实体(entities)
- 使用关联术语搜索实体
与术语表相关的UI都可以在GLOSSARY的Tab下找到。
Classification Propagation
- Classification propagation enables classifications associated to an entity to be automatically associated with other related entities of the entity. This is very useful in dealing with scenarios where a dataset derives it data from other datasets - like a table loaded with data in a file, a report generated from a table/view, etc.
- For example, when a table is classified as PII, tables or views that derive data from this table (via CTAS or ‘create view’ operation) will be automatically classified as PII.
Consider the following lineage where data from a ‘hdfs_path’ entity is loaded into a table, which is further made available through views. We will go through various scenarios to understand the classification propagation feature.
exp
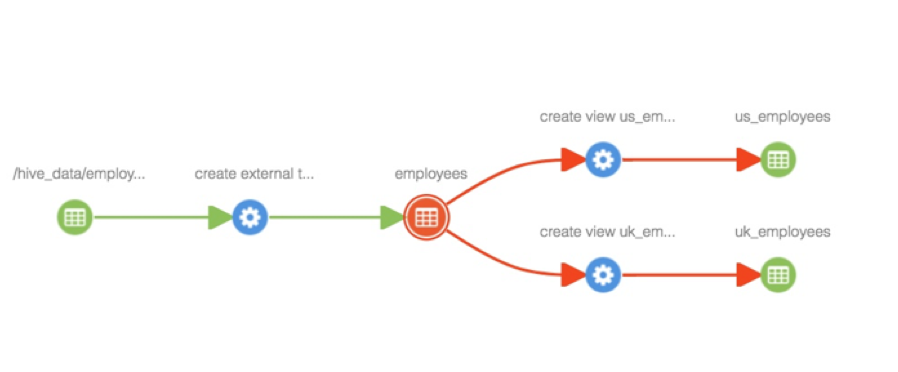
Add classification to an entity
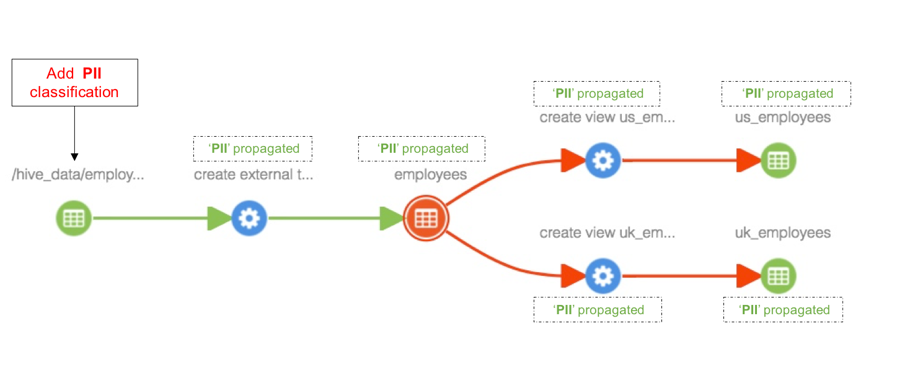
When classification ‘PII’ is added to ‘hdfs_path’ entity, the classification is propagated to all impacted entities in the lineage path, including ‘employees’ table, views ‘us_employees’ and ‘uk_employees’ - as shown below.
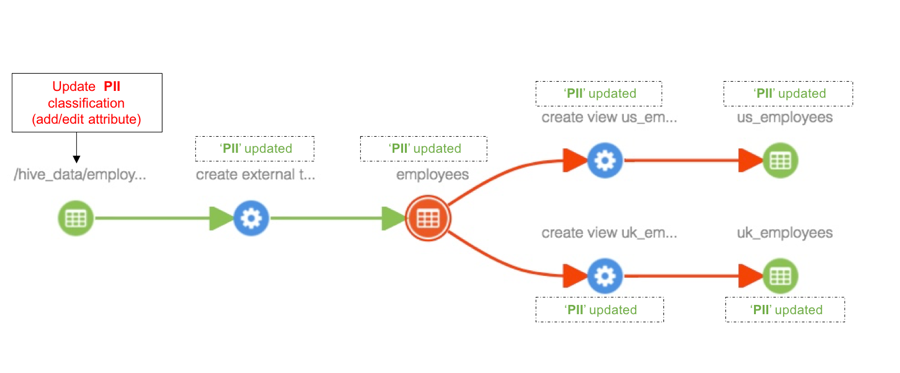
Update classification associated with an entity
Any updates to classifications associated with an entity will be seen in all entities the classification is propagated to as well.
Remove classification associated with an entity
When a classification is deleted from an entity, the classification will be removed from all entities the classification is propagated to as well.
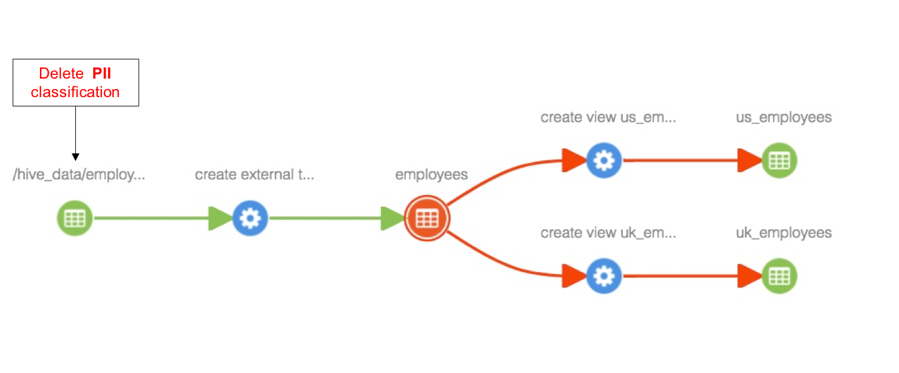
Add lineage between entities
When lineage is added between entities, for example to capture loading of data in a file to a table, the classifications associated with the source entity are propagated to all impacted entities as well. For example, when a view is created from a table, classifications associated with the table are propagated to the newly created view as well.
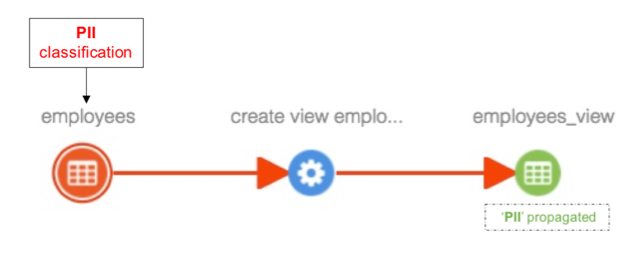
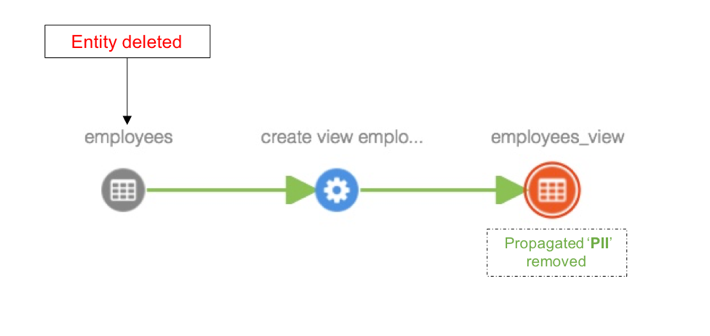
Delete an entity
Case 1: When an entity is deleted, classifications associated with this entity will be removed from all entities the classifications are propagated to. For example. when employees table is deleted, classifications associated with this table are removed from ‘employees_view’ view.
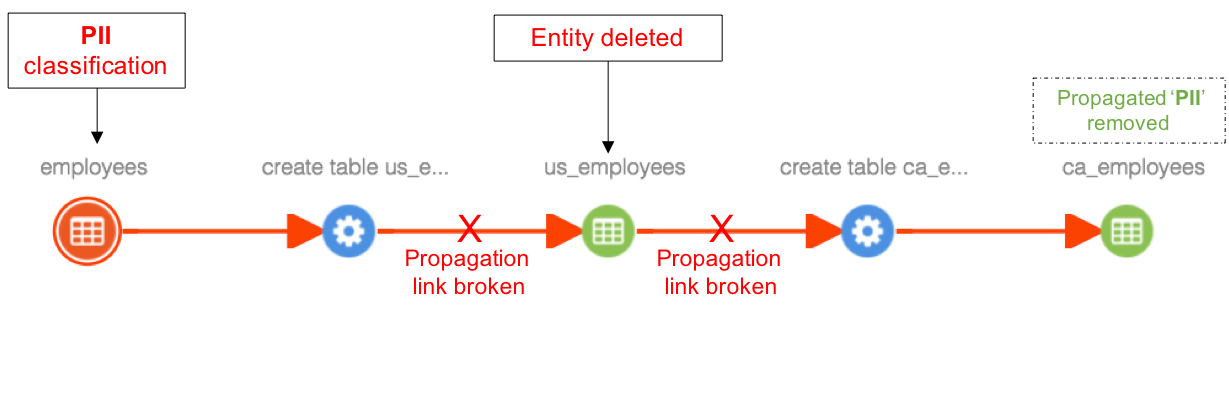
Case 2: When an entity is deleted in the middle of a lineage path, the propagation link is broken and previously propagated classifications will be removed from all derived entities of the deleted entity. For example. when ‘us_employees’ table is deleted, classifications propagating through this table (PII) are removed from ‘ca_employees’ table, since the only path of propagation is broken by entity deletion.
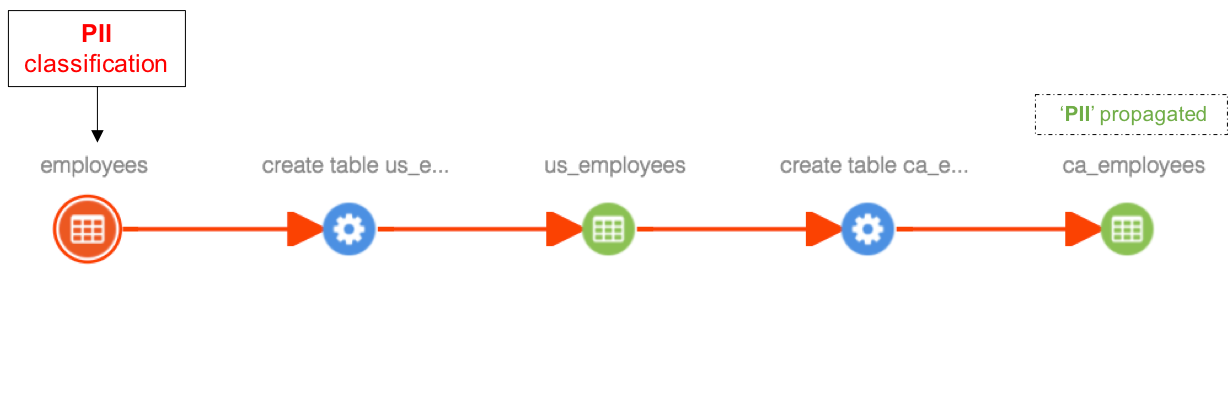
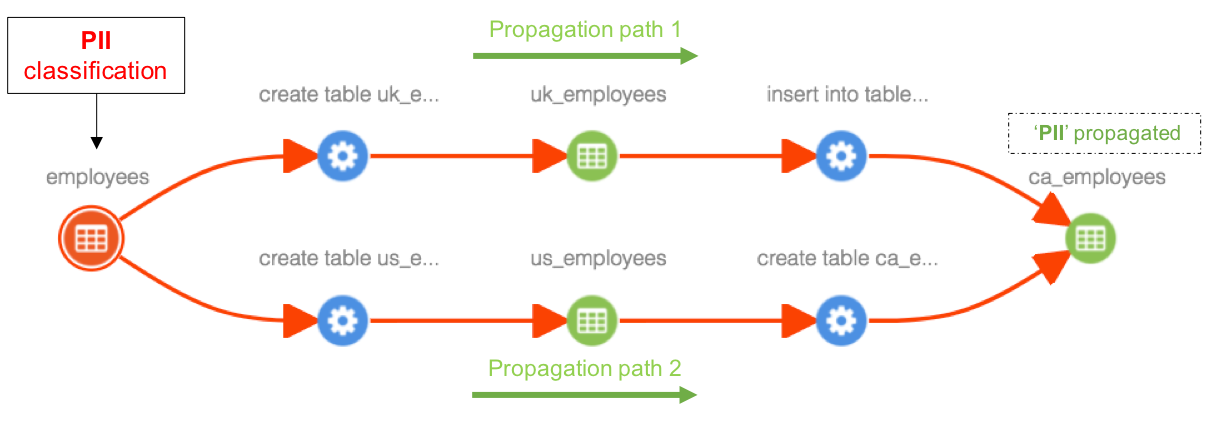
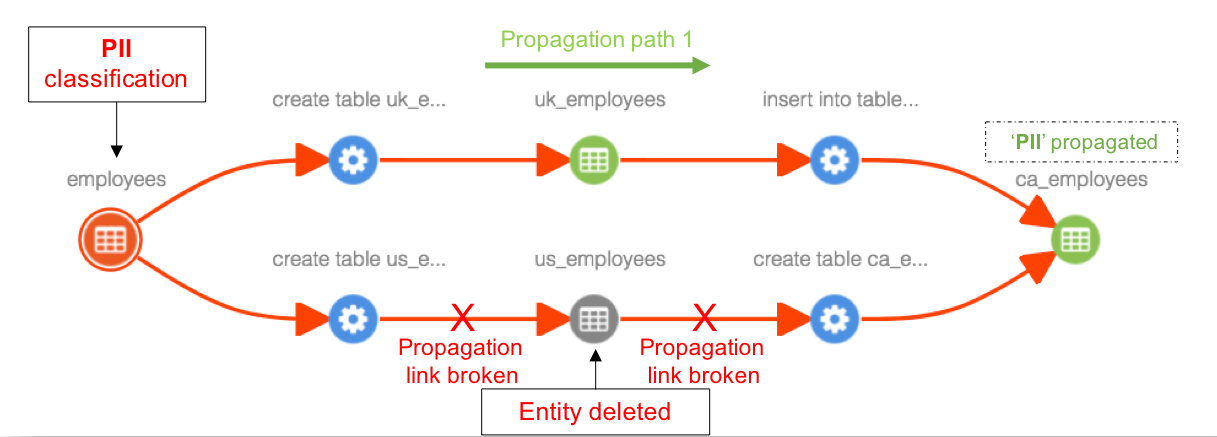
Case 3: When an entity is deleted in the middle of a lineage path and if there exists alternate path for propagation, previously propagated classifications will be retained. For example. when ‘us_employees’ table is deleted, classifications propagating (PII) through this table are retained in ‘ca_employees’ table, since there are two propagation paths available and only one of them is broken by entity deletion.
Notifications from Apache Atlas

1. Atlas发出的通知
Apache Atlas将有关元数据更改的通知发送到名为ATLAS_ENTITIES的Kafka主题。对元数据更改感兴趣的应用程序可以监视这些通知例如,Apache Ranger处理这些通知以根据分类授权数据访问。
1.1 Notifications - V2: Apache Atlas version 1.0
Apache Atlas 1.0发送有关元数据的以下操作的通知。
1 | ENTITY_CREATE: sent when an entity instance is created |
通知包括以下数据。
1 | AtlasEntity entity; |
2.发送给Atlas的通知
通过向Kafka主题ATLAS_HOOK发送通知,可以向Apache Atlas通知元数据和血缘的修改。 Apache Hive/Apache HBase/Apache Storm/Apache Sqoop的Atlas hook使用此机制向Apache Atlas通知感兴趣的事件。
1 | ENTITY_CREATE : create an entity. For more details, refer to Java class HookNotificationV1.EntityCreateRequest |
安装组建选择
- apache-atlas-1.2.0-sources.tar.gz
- solr-5.5.1.tgz
- hbase-1.1.2.tar.gz
本地编译之后再安装,启动后如下所示
Hive血缘关系导入
官网上有对应的方法,实际操作的时候有一些问题,需要一些额外操作,暂时不展开。
需要在hive中安装对应的hook用来捕获数据,在hive-site.xml中添加如下内容
1 | <property> |
Hive hook 可捕获以下操作:
- create database
- create table/view, create table as select
- load, import, export
- DMLs (insert)
- alter database
- alter table
- alter view
源码分析
Hbase数据变化流程图
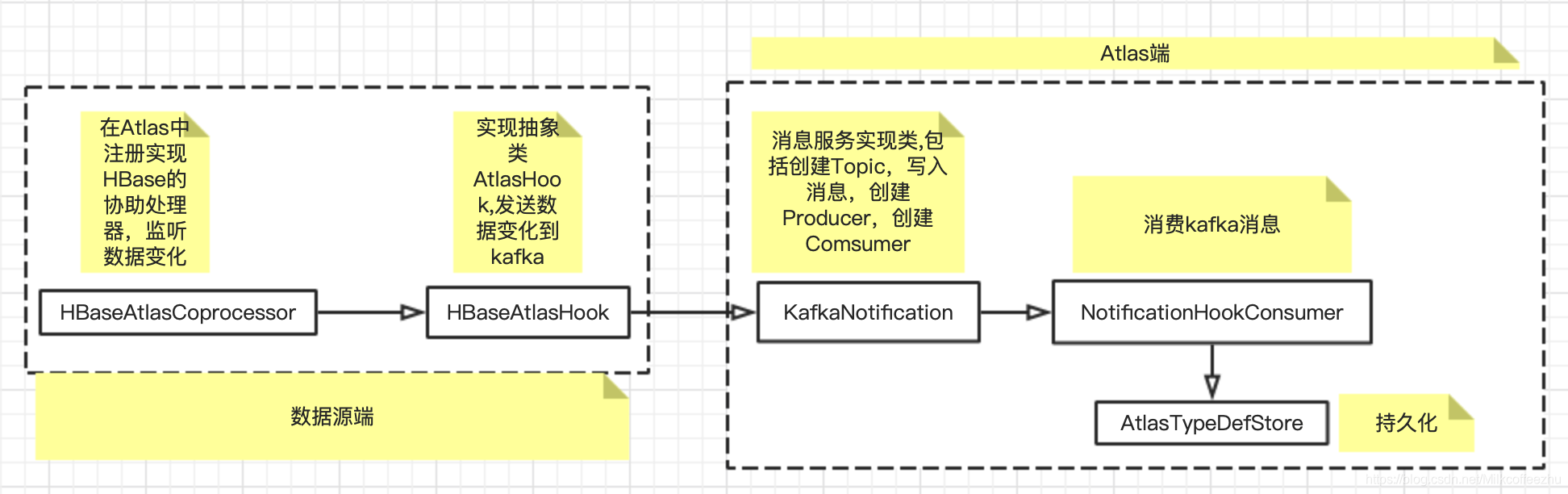
实现对HBaseAtlasHook这个类的加载
1 | public class HBaseAtlasCoprocessor implements MasterObserver, RegionObserver, RegionServerObserver, BulkLoadObserver { |
获取HBase变化的数据
1 | public class HBaseAtlasCoprocessor extends HBaseAtlasCoprocessorBase { |
HBaseAtlasHook相关源码
1 | // This will register Hbase entities into Atlas |
AtlasHook 相关源码
1 | /** |
Notification相关源码
1 | /** |
消费kafka消息
start()实现一个后台的job消费从hook发送过来的数据
1 | /** |
消费消息的处理逻辑
1 |
|
将消息持久化
1 | /** |
数据的校验以及,以及格式的转换
1 | public class EntityMutationResponse { |
持久化数据
1 |
|
Hive Hooks
关于数据治理和元数据管理框架,业界有许多开源的系统,比如Apache Atlas,这些开源的软件可以在复杂的场景下满足元数据管理的需求。其实Apache Atlas对于Hive的元数据管理,使用的是Hive的Hooks。需要进行如下配置:
1 | <property> |
通过Hook监听Hive的各种事件,比如创建表,修改表等,然后按照特定的格式把收集的数据推送到Kafka,最后消费元数据并存储。
Hooks 是一种事件和消息机制, 可以将事件绑定在内部 Hive 的执行流程中,而无需重新编译 Hive。Hook 提供了扩展和继承外部组件的方式。根据不同的 Hook 类型,可以在不同的阶段运行。
- Pre-execution Hook 在执行引擎执行查询之前被调用。这个需要在 Hive 对查询计划进行过优化之后才可以使用。
- Post-execution hooks 在执行计划执行结束结果返回给用户之前被调用。
- Failure-execution hooks 在执行计划失败之后被调用。
- Pre-driver-run 和 post-driver-run 是在查询运行的时候运行的。
- Pre-semantic-analyzer and Post-semantic-analyzer Hook 在 Hive 对查询语句进行语义分析的时候调用。
对于Hive Hooks,给出hive.exec.post.hook的使用案例,该Hooks会在查询执行之后,返回结果之前运行。
Hive hook是hive的钩子函数,可以嵌入HQL执行的过程中运行,比如下面的这几种情况。
具体实现代码如下:
1 | public class CustomPostHook implements ExecuteWithHookContext { |
demo
1 | public class hook_test implements ExecuteWithHookContext { |
使jar包临时生效
1 | add jar /opt/lagou/servers/hive-2.3.7/lib/hive_hooks-1.0-SNAPSHOT.jar; |
执行一个sql之后的结果
1 | show tables; |
atlas中具体的例子
BaseHiveEvent
1 | protected String getQualifiedName(List<AtlasEntity> inputs, List<AtlasEntity> outputs) throws Exception { |
HiveHook
1 | public HiveHook() { |
本文链接: http://woaixiaoyuyu.github.io/2021/07/28/Apache%20Atlas%20%E6%96%87%E6%A1%A3/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!