
对hive/spark-sql/presto中的join使用时的策略进行一些分析和理解。
大表选择big_table,小表选择small table
Sql
1 | --hive/spark-sql |
hive
执行计划如下。
1 | STAGE DEPENDENCIES: |
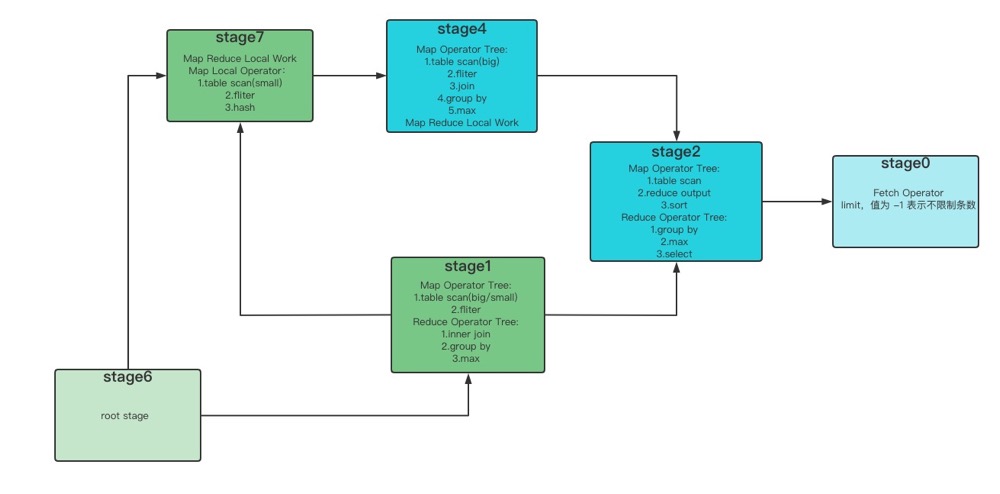
可以看到按照常理来说,在普通的join当中,左边的表的内容会被加载进内存,但是在本次案例中,依然是右边的表(small table)的内容被加载进了内存。当我们更换join的前后顺序以后,发现依然是小表加载进了内存,因为在hive集群上开启了hive优化,默认将小表入读内存,所以执行普通的join时不用考虑表名的书写顺序。
spark
大表在左,执行如下。
1 | == Physical Plan == |
大表在右,执行如下。
1 | == Physical Plan == |
整理一下执行流程,如下。
1 | --big join small |
可以看到关键部分的结果是一样的,因为开启了一些默认优化的机制。
Spark will perform (or be forced by us to perform) joins in two different ways: either using Sort Merge Joins if we are joining two big tables, or Broadcast Joins if at least one of the datasets involved is small enough to be stored in the memory of the single all executors.
Broadcast Hash Join
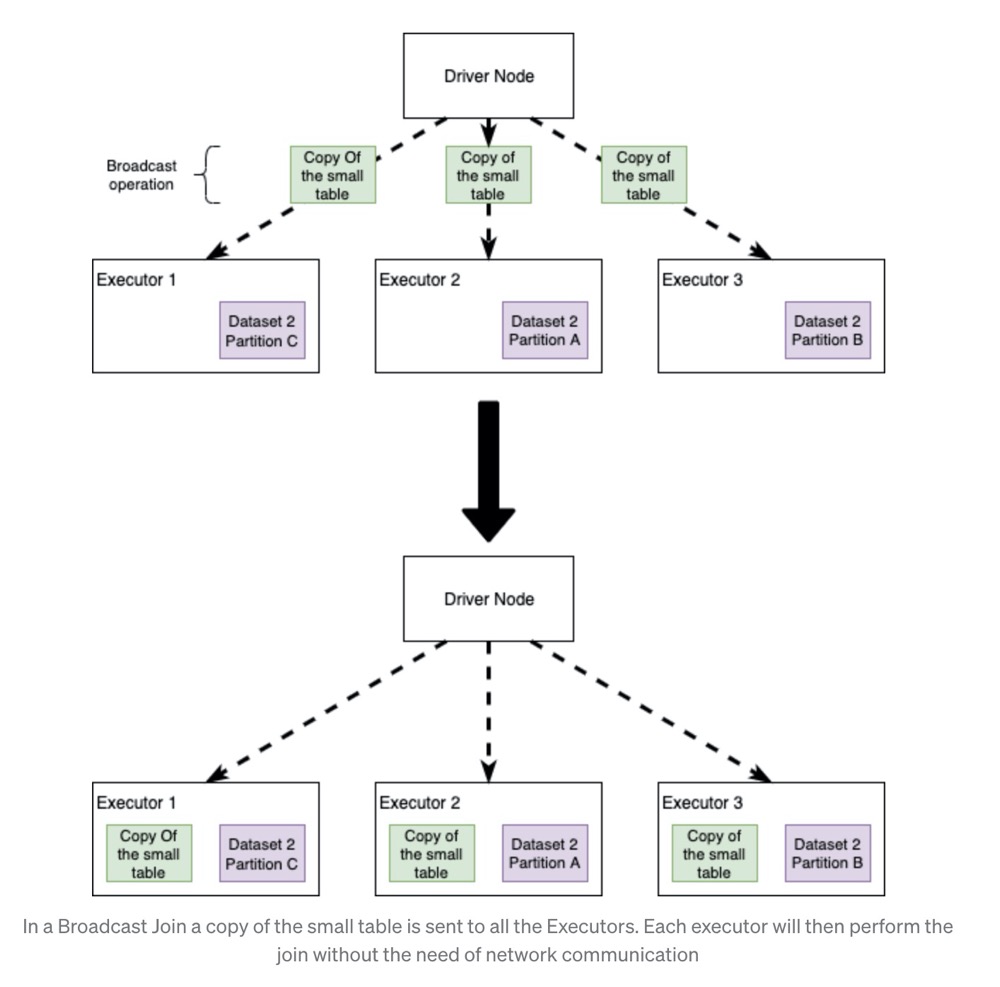
Broadcast Hash Join 的实现是将小表的数据广播到 Spark 所有的 Executor 端,这个广播过程和我们自己去广播数
据没什么区别:
- 利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端
- 在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端
- 在 Executor 端使用广播的数据与大表进行 Join 操作(实际上是执行map操作)
这种 Join 策略避免了 Shuffle 操作。一般而言,Broadcast Hash Join 会比其他 Join 策略执行的要快。
使用这种 Join 策略必须满足以下条件:
- 小表的数据必须很小,可以通过 spark.sql.autoBroadcastJoinThreshold 参数来配置,默认是 10MB
- 如果内存比较大,可以将阈值适当加大
- 将 spark.sql.autoBroadcastJoinThreshold 参数设置为 -1,可以关闭这种连接方式
- 只能用于等值 Join,不要求参与 Join 的 keys 可排序
Shuffle Hash Join
当表中的数据比较大,又不适合使用广播,这个时候就可以考虑使用 Shuffle Hash Join。
Shuffle Hash Join 同样是在大表和小表进行 Join 的时候选择的一种策略。它的计算思想是:把大表和小表按照相同的分区算法和分区数进行分区(根据参与 Join 的 keys 进行分区),这样就保证了 hash 值一样的数据都分发到同一个分区中,然后在同一个 Executor 中两张表 hash 值一样的分区就可以在本地进行 hash Join 了。在进行 Join 之前,还会对小表的分区构建 Hash Map。Shuffle hash join 利用了分治思想,把大问题拆解成小问题去解决。

要启用 Shuffle Hash Join 必须满足以下条件:
- 仅支持等值 Join,不要求参与 Join 的 Keys 可排序
- spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为true,也就是默认情况下选择 Sort Merge Join小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold *spark.sql.shuffle.partitions(默认值200mb)
- 而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是a.stats.sizeInBytes * 3 < = b.stats.sizeInBytes
Shuffle Sort Merge Joins
前面两种 Join 策略对表的大小都有条件的,如果参与 Join 的表都很大,这时候就得考虑用 Shuffle Sort Merge Join了。
Shuffle Sort Merge Join 的实现思想:
- 将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区对每个分区内的数据进行排序
- 排序后再对相应的分区内的记录进行连接
- 无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有序。从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。
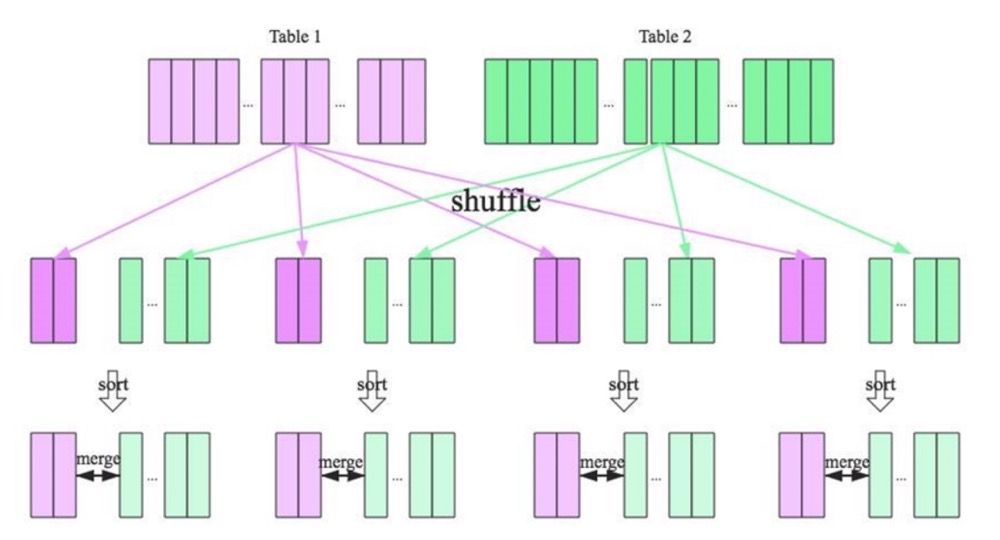
要启用 Shuffle Sort Merge Join 必须满足以下条件:
- 仅支持等值 Join,并且要求参与 Join 的 Keys 可排序
Cartesian product join
如果 Spark 中两张参与 Join 的表没指定连接条件,那么会产生 Cartesian product join,这个 Join 得到的结果其实就是两张表行数的乘积。
因为数据量普遍很大,严禁使用!
presto
执行计划关键是下面这段。
1 | Fragment 2 [HASH] |
Presto中 join 的默认算法是broadcast join,即将 join 左边的表分割到多个 worker ,然后将join 右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
在默认情况下,presto使用distributed hash join算法,在这种算法中,join左右两边的表都会根据join键的值进行分区。左表的每个分区都会被通过网络传入到右表所在分区的worker节点上。也就是说,在进行join关联的时候,会先把右表的所有分区全部分布到各个计算节点上保存,然后等待将左表中的各个分区依次通过网络传输stream 到相应的计算节点上进行计算。由于右表的所有分区需要全部分布到各个节点上进行存储,所以有一个限制:就是集群中所有内存的代销一定要大于右表的大小。
如果你在执行join查询的时候看到错误:task exceeded max memory size,那么这经常意味着join连接的右表大于集群所有内存的大小。presto不会自动进行join两边表 顺序的优化,因此在执行join查询的时候,请确保大表放在join的左边,小表放在join右边。
必须注意这一点,因为没有像hive那样开启优化–默认将小表放入内存。
本文链接: http://woaixiaoyuyu.github.io/2021/07/10/Hivesparkpresto%20join%E7%AD%96%E7%95%A5/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!